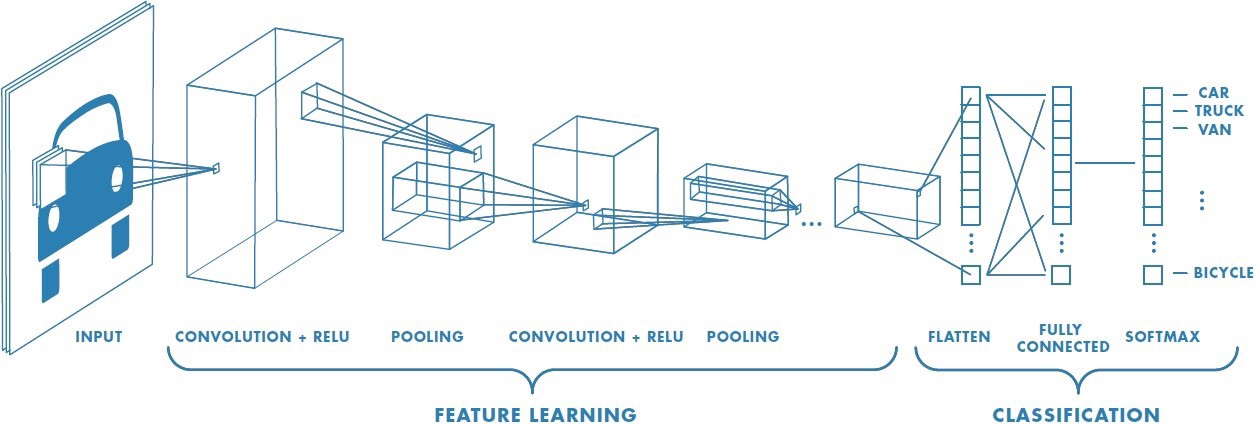
Convolutional Neural Network (CNN) adalah salah satu algoritme deep learning. CNN sudah dikenal luas dalam bidang pengolahan gambar, namun kini CNN juga mulai diterapkan di bidang-bidang lain seperti pengolahan kata, pengolahan time series data, pengolahan video, dan bidang lainnya.
Bila kita menggunakan keras, maka akan ada tiga jenis CNN layer yang dapat kita gunakan, yaitu Conv1D, Conv2D, dan Conv3D. Walaupun memiliki kesamaan prinsip kerja, namun ketiganya digunakan untuk menyelesaikan kasus yang berbeda. Sekarang mari kita bahas perbedaan diantara ketiga CNN layer tersebut.
Bila Anda belum memahami dasar dari CNN, maka saya sarankan untuk mempelajari dasar-dasar CNN terlebih dahulu sebelum melanjutkan membaca artikel ini. Misalnya melalui artikel “A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way” ini. Artikel tersebut membahas dasar-dasar CNN dengan ilustrasi yang menarik, sehingga mudah dipahami.
Penggunaan
Masing-masing jenis CNN layer digunakan untuk kasus dan obyek pemrosesan yang berbeda. Table 1 berikut merangkum contoh penggunaan masing-masing CNN layer.
| Conv1D | Conv2D | Conv3D |
| Natural Language Processing | 2D Image Processing | Video Processing |
| Time series data analysis | 3D Image Processing | |
| Audio processing |
Agar dapat memahami mengapa terdapat perbedaan CNN layer yang digunakan pada kasus tersebut, maka kita harus memahami cara kerja dari masing-masing CNN layer tersebut.
Cara Kerja
Kita mulai dari cara kerja Conv2D karena layer ini adalah dasar dari konsep CNN yang nantinya dikembangkan menjadi Conv1D dan Conv3D. Conv2D juga merupakan CNN layer yang paling sering kita temui di berbagai buku dan tutorial tentang CNN, khususnya pada topik pengolahan gambar.
Conv2D

Gambar 1 adalah ilustrasi Conv2D yang diimplementasikan ke dalam pixel gambar RGB. Tiap pixel berada di posisi tertentu dalam koordinat X dan Y. Tiap pixel terdiri dari 3 kanal (channel) atau vektor (vector) warna, yaitu merah (Red), hijau (Green), dan biru (Blue). Dalam praktiknya, vektor kata disimpan array 1 dimensi. Sebagai contoh, pixel warna merah direpresentasikan menggunakan vektor [255, 0, 0].
Filter dalam Gambar 1 berukuran 2 x 2 pixel. Filter tersebut akan memindai gambar secara vertikal (X axis) dan horizontal (Y axis). Karena contoh pada Gambar 1 berukuran 10 x 9 pixel, maka filter tersebut akan memindai sebanyak 9 x 8 atau 72 kali.
Filter dalam topik CNN juga dikenal dengan nama lain seperti kernel, convolution matrix, mask, atau feature detector.
Tujuan dari penggunaan filter ini adalah untuk mendapatkan feature dari gambar. Dalam praktiknya, feature yang dicari oleh CNN filter dapat berupa tepi (edge) atau pola (pattern) lainnya dari obyek dalam gambar. Bila tertarik lebih dalam, artikel berjudul What exactly does CNN see? ini memberikan visualisasi atas hasil perhitungan CNN filter.
Conv1D

Gambar 2 adalah ilustrasi Conv1D yang diimplementasikan ke dalam text processing. Pada contoh dalam Gambar 2, terdapat sebuah teks yang terdiri dari 9 kata. Agar dapat diolah menggunakan CNN, kata tersebut di encode menjadi vektor. 1 vektor merupakan representasi dari 1 kata. Sehingga dalam contoh di Gambar 2, terdapat 9 vektor yang merupakan representasi dari 9 kata.
Pada contoh Gambar 2, 1 vektor kata terdiri dari 6 nilai (value). Misalnya, kata “Love” dapat di encode ke dalam vektor [1, 1, 1, 0, 0, 0]. Pada prinsipnya, ini mirip seperti nilai 1 pixel dalam Conv2D yang terdiri dari 3 nilai RGB.
Filter dalam Gambar 2 berukuran 2 kata. Filter tersebut akan memindai teks dari awal hingga akhir (X axis). Karena dalam contoh pada Gambar 2 terdapat 9 kata, maka filter tersebut akan memindai sebanyak 8 kali.
Conv3D
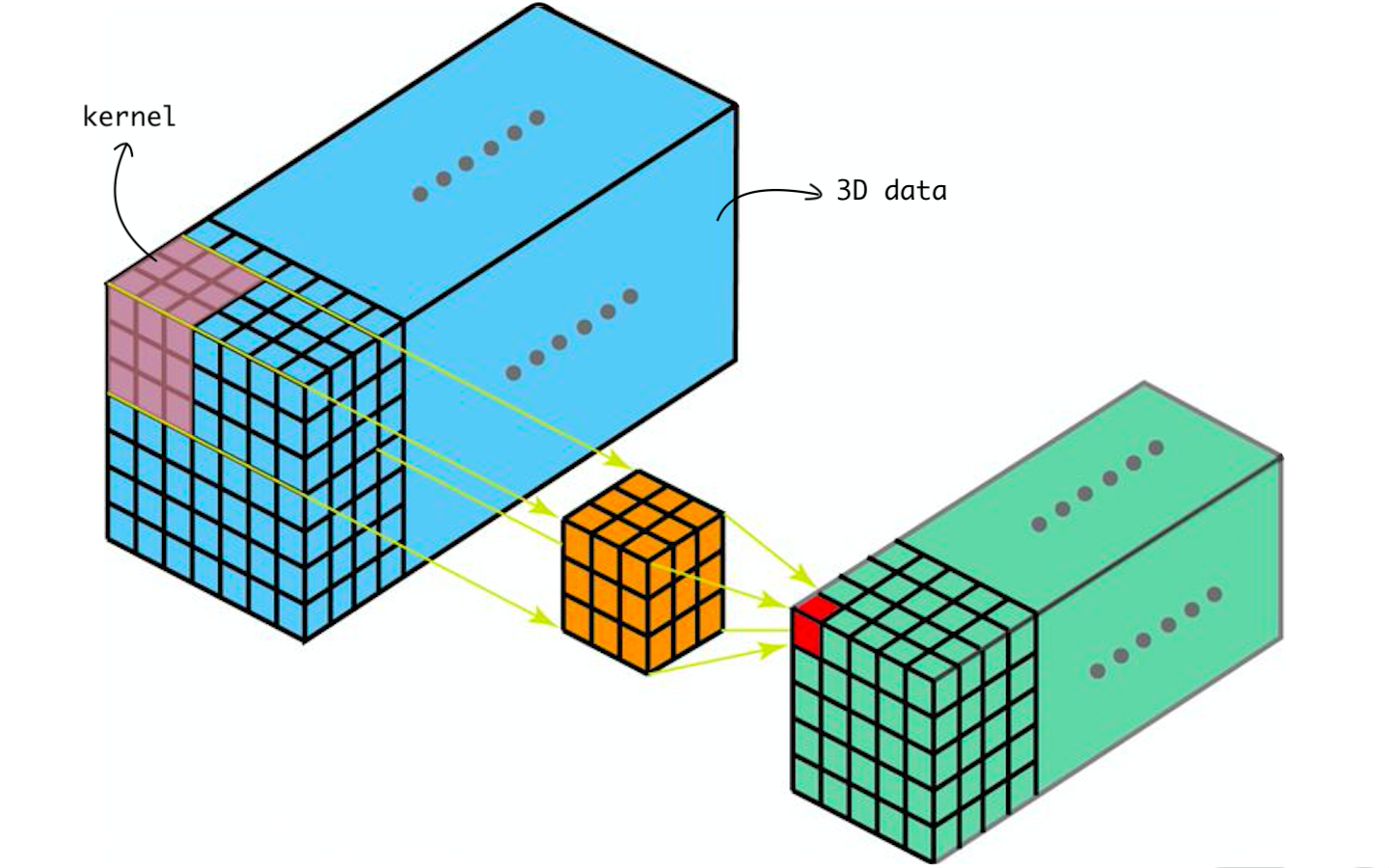
Pada dasarnya, Conv3D mengolah data 3 dimensi. Contohnya adalah video. Video sebenarnya merupakan sebuah gambar, namun jumlahnya sangat banyak dan ditampilkan secara berurutan. Dengan kata lain video adalah sebuah time series images.
Pada Conv3D, filter memindai secara horizontal (X axis), vertikal (Y axis), dan mendalam (Z axis). Conv3D banyak digunakan untuk mengolah data 3D seperti data Magnetic Resonance Imaging (MRI) atau Computerized Tomography (CT).
Dimensi Input Space pada Keras
Bila anda menggunakan keras, maka terdapat perbedaan dimensi input space yang dimasukkan sebagai parameter saat melakukan inisialisasi CNN layer. Tabel 2 berikut ini merangkum perbedaan input space pada ketiga jenis CNN layer tersebut.
| Dimensi Input Space | ||
| Conv1D | 3D | batch_size, input_dim1, channels |
| Conv2D | 4D | batch_size, input_dim1, input_dim2, channels |
| Conv3D | 5D | batch_size, input_dim1, input_dim2, input_dim3, channels |
Catatan, urutan input pada Tabel 2 disusun berdasarkan asumsi nilai data_format='channels_last'.
Sebagai contoh:
Data input: 1 detik suara stereo (2 kanal) 44100 Hz
Dimensi input Conv1D: (batch_size, 44100, 2)
Data input: 2 detik suara mono (1 kanal) 44100 Hz
Dimensi input Conv1D: (batch_size, 88200, 1)
Data input: gambar RGB 32 x 16 pixel
Dimensi input Conv2D: (batch_size, 32, 16, 3)
Data input: gambar grayscale 16 x 32 pixel
Dimensi input Conv2D: (batch_size, 16, 32, 1)
Data input: 1 detik video RGB berukuran 128 x 80 pixel dengan kecepatan putar 24 frame per second (fps)
Dimensi input Conv3D: (batch_size, 24, 128, 80, 3)
Data input: 2 detik video grayscale berukuran 80 x 128 pixel dengan kecepatan putar 24 frame per second (fps)
Dimensi input Conv3D: (batch_size, 48, 80, 128, 1)
Kesimpulan
Kesimpulan dari pembahasan tentang perbedaan Conv1D, Conv1D, dan Conv1D dalam dilihat pada Tabel 3 berikut.
| Conv1D | Conv2D | Conv3D | |
| Dimensi keras input space | 3 D | 4 D | 5 D |
| Dimensi data input | 2 D | 3 D | 4 D |
| Dimensi filter | 2 D | 3 D | 4 D |
| Dimensi data output | 2 D | 3 D | 4 D |
| Gerakan filter | 1 D | 2 D | 3 D |
Semoga tulisan ini dapat bermanfaat bagi kita semua.
Daftar Pustaka
- What are the differences between Convolutional1D, Convolutional2D, and Convolutional3D?
- Conv1D, Conv2D and Conv3D
- A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way
- What exactly does CNN see?
- Example of 1D ConvNet filter
- What is the shape of conv3d and conv3d_transpose?
- Keras Conv1D: Working with 1D Convolutional Neural Networks in Keras
- How to Develop 1D Convolutional Neural Network Models for Human Activity Recognition