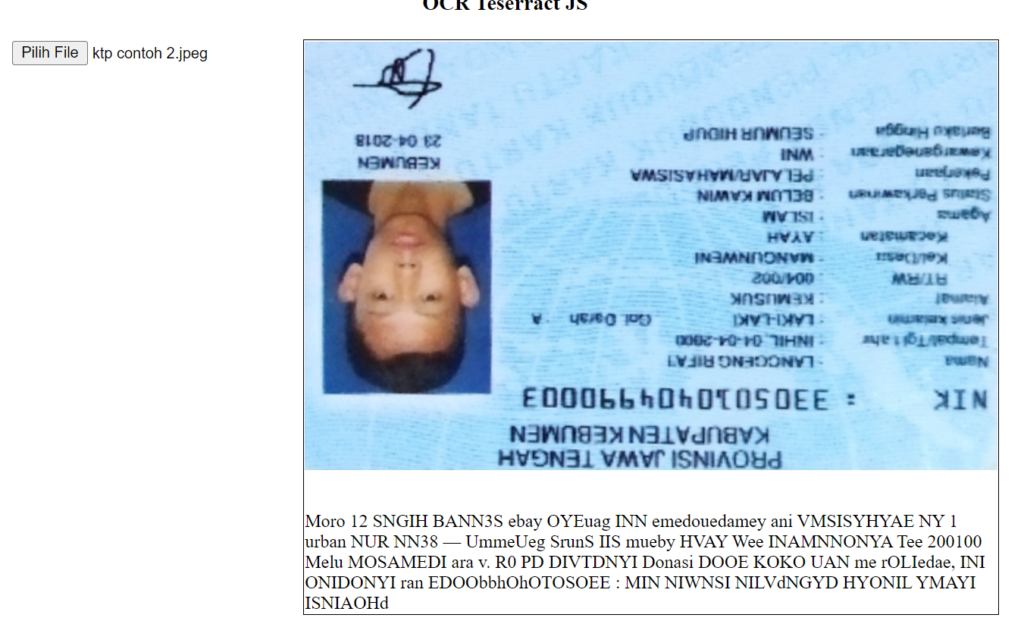
Tesseract.recognize(files, "ind").then(({ data: { text } }) => {
let d_split = text.split('\n');
$.each(d_split, function(i, item) {
if(item.toUpperCase().includes('NIK')){
$('#hasil').html('<center><img decoding="async" src="'+event.target.result+'" width="100%" /></center><br><br>' + item.replace('NIK', '').replace(' ', '').replace(':', ''));
}
});
});