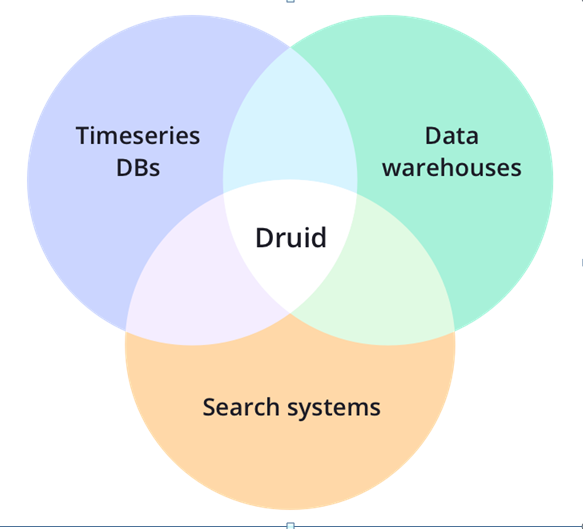
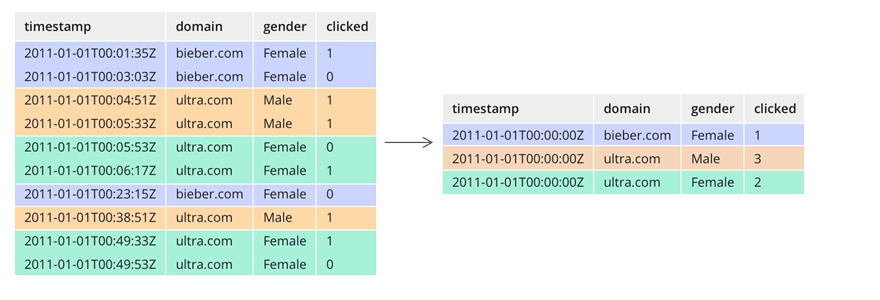
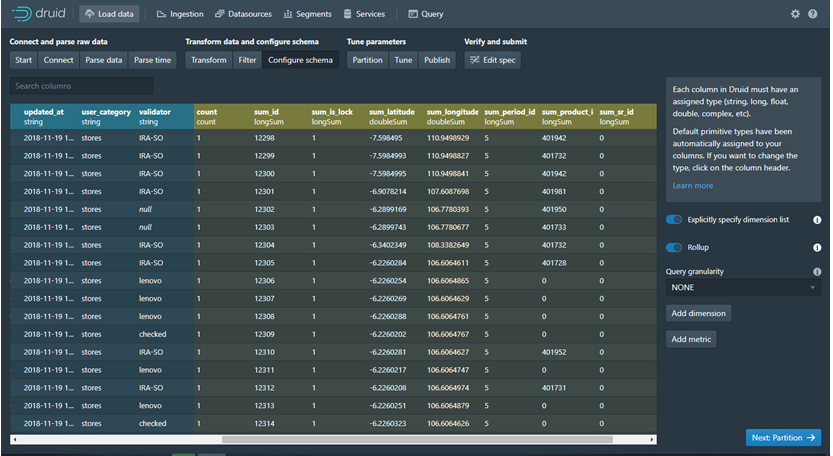
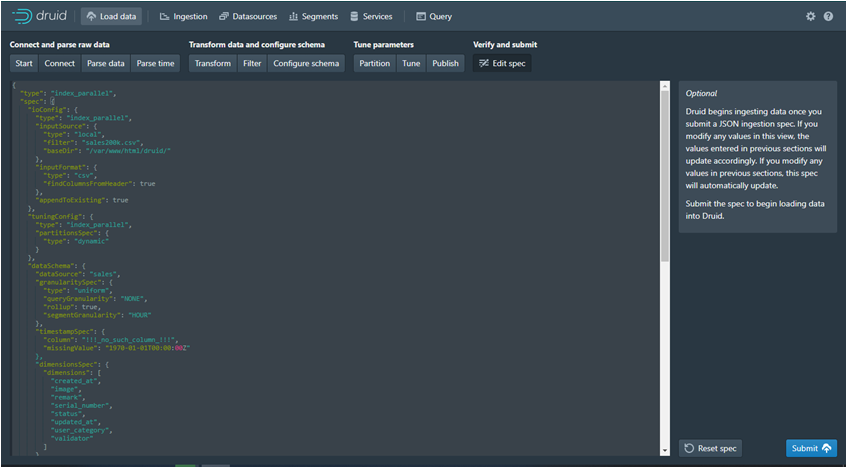
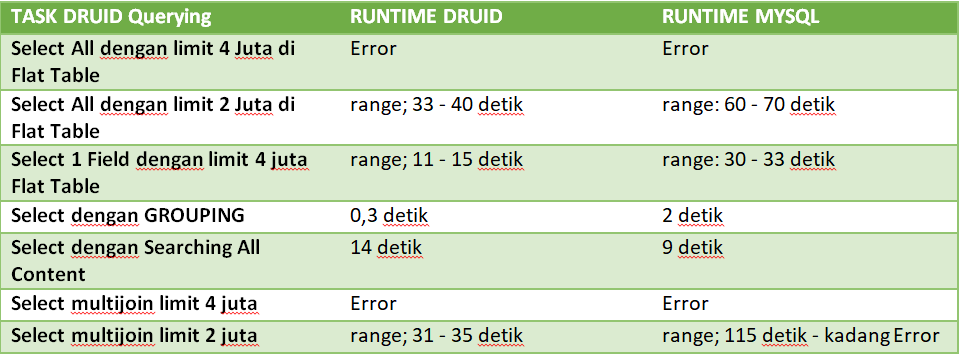
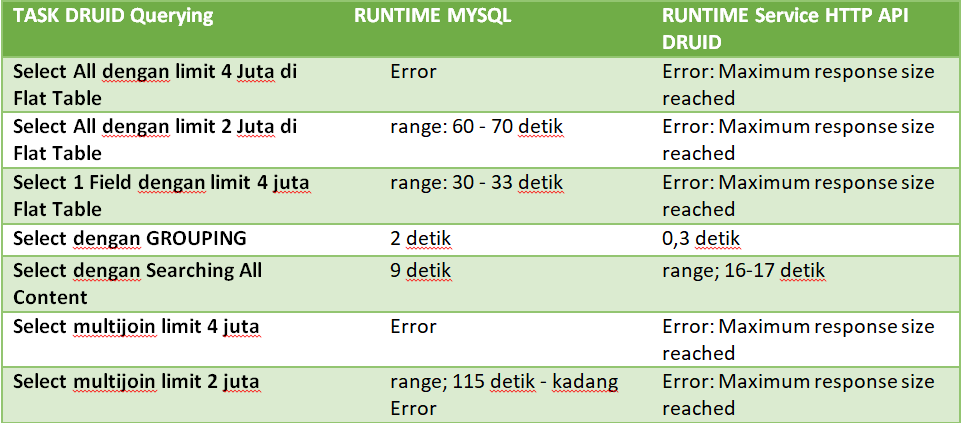
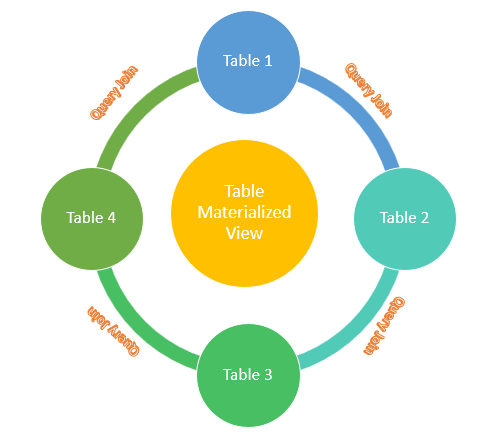
Berdasarkan Gambaran Diatas bisa akita lihat Hasil query dari beberapa table akan menghasilkan single table. Bagaimana caranya?
Berikut kita masuk ke topik utama yaitu Teknik Materialized View di Database MYSQL.
Sebagai Contoh disini saya membuat database untuk penjualan Rumah Makanan yang sederhana:
1. Table user
CREATE TABLE `user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`phone` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`role_id` INT(11) NULL DEFAULT NULL,
`status` TINYINT(4) NULL DEFAULT ‘1’,
`created_at` DATETIME NOT NULL DEFAULT current_timestamp(),
`updated_at` DATETIME NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`) USING BTREE,
INDEX `role_id` (`role_id`) USING BTREE
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB
AUTO_INCREMENT=2;
2. Table role
CREATE TABLE `role` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`created_at` DATETIME NOT NULL DEFAULT current_timestamp(),
`updated_at` DATETIME NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`) USING BTREE
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB
AUTO_INCREMENT=4;
3. Table menu (menu makanan)
CREATE TABLE `menu` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`price` DOUBLE(22,0) NULL DEFAULT NULL,
`status` TINYINT(4) NULL DEFAULT NULL,
`created_at` DATETIME NOT NULL DEFAULT current_timestamp(),
`updated_at` DATETIME NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`) USING BTREE
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB
AUTO_INCREMENT=6;
4. Table Invoice
CREATE TABLE `invoice` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`user_id` INT(11) NULL DEFAULT NULL,
`created_at` DATETIME NOT NULL DEFAULT current_timestamp(),
`updated_at` DATETIME NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`) USING BTREE,
INDEX `user_id` (`user_id`) USING BTREE
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB
AUTO_INCREMENT=2;
5. Table invoice_detail
CREATE TABLE `invoice_detail` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`invoice_id` INT(11) NULL DEFAULT NULL,
`menu_id` INT(11) NULL DEFAULT NULL,
`price` DOUBLE(22,0) NULL DEFAULT NULL,
`quantity` INT(11) NULL DEFAULT NULL,
`created_at` DATETIME NOT NULL DEFAULT current_timestamp(),
`updated_at` DATETIME NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`) USING BTREE,
INDEX `menu_id` (`menu_id`) USING BTREE,
INDEX `invoice_id` (`invoice_id`) USING BTREE
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB
AUTO_INCREMENT=2;
6. View invoice_report_list ini adalah view yang akan kita Materialized.
DROP TABLE IF EXISTS `invoice_report_list`;
CREATE ALGORITHM=UNDEFINED SQL SECURITY DEFINER VIEW `invoice_report_list` AS SELECT i.id,id.invoice_id, id.price, id.quantity, i.created_at AS sale_date, u.name AS cahsier, m.name AS menu_name, r.name AS role_name, r.id AS role_id FROM invoice_detail id JOIN invoice i ON (id.invoice_id = i.id) JOIN user u ON (i.user_id = u.id) JOIN menu m ON (id.menu_id = m.id) JOIN role r ON (u.role_id = r.id) ;
Berikut beberapa Teknik Materialized View:
1. Materialize View dengan Event Scheduller dan Store Routine (Tidak Real Time).
Event Scheduller digunakan untuk memanagement Eksekusi suatu event dalam Batabase MYSQL dan Task dijalankan secara barkala atau sesuai dengan penjadwalan. Event Scheduller dalam Materialized View ini digunakan sebagai perintah penjadwalan yang kemudian digunakan untuk eksekusi secara berkala sehingga hasil Materialized View akan terupdate berdasarkan Jadwal dari Event Scheduller. Disini selain menggunakan Event scheduler juga menggunakan Store Routine. Store Routine adalah semacam prosedur fungsi yang bisa digunakan di MYSQL. Dengan menggunakan DB Rumah makan diatas, Berikut Langkah Materialized View:
- Kita akan membuat Table dengan nama invoice_report_mv_event_sche sebagai Materialized View nya yang memiliki field sama dengan View invoice_report_list:
CREATE TABLE `invoice_report_mv_event_sche` (
`id` INT(11) NULL DEFAULT NULL,
`invoice_id` INT(11) NULL DEFAULT NULL,
`price` DOUBLE(22,0) NULL DEFAULT NULL,
`quantity` INT(11) NULL DEFAULT NULL,
`sale_date` DATETIME NULL DEFAULT NULL,
`chasier` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`menu_name` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`role_name` VARCHAR(50) NULL DEFAULT NULL COLLATE ‘utf8mb4_general_ci’,
`role_id` INT(11) NULL DEFAULT NULL
)
COLLATE=‘utf8mb4_general_ci’
ENGINE=InnoDB;
- Buat Store Routine yang digunakan untuk refresh Table invoice_report_mv_event_sche.
CREATE DEFINER=`root`@`localhost` PROCEDURE `store_routine_mv`(
IN `rc` INT
)
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ”
BEGIN
TRUNCATE TABLE invoice_report_mv_event_sche;
INSERT INTO invoice_report_mv_event_sche
select * from invoice_report_list;
SET rc = 0;
END
- Buat Event untuk melakukan penjadwalan refresh dari Store Routine yang telah kita buat tadi. Event disini saya buat akan dijadwalkan setiap 1 Jam akan dieksekusi
CREATE DEFINER=`root`@`localhost` EVENT `event_scheduller_mv`
ON SCHEDULE
EVERY 1 HOUR STARTS ‘2020-10-25 10:46:00’
ON COMPLETION NOT PRESERVE
ENABLE
COMMENT ”
DO BEGIN
CALL `store_routine_mv`(@rc);
END
- Untuk menjalankan Event Scheduller di system dengan menggunakan command berikut:
SET GLOBAL event_scheduler = ON;
- Apabila semua step diatas sudah dilaksanakan maka table invoice_report_mv_event_sche akan ter refresh setiap 1 Jam.