Author: Dhendik Dwi Prasetyo
PROGRAMMING ADDICT











CategoriesProgramming
Performa Apache Druid dibanding dengan ekosistem MYSQL
A. Pengenalan Apache Druid
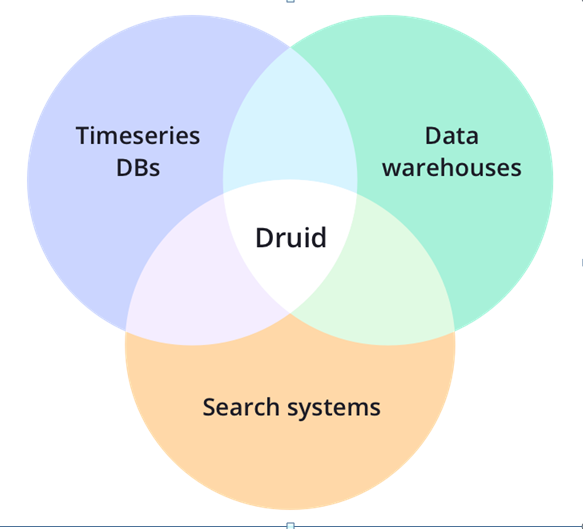
Apache Druid adalah Open Source untuk mendistribusikan data penyimpanan. Core Desain Druid menggabungkan ide-ide dari Data Warehouse Timeseries Database, dan Search System untuk membuat analisa dengan performa terbaik untuk pencarian di database secara realtime khusus kasus tertentu. Apache Druid paling tepat digunakan untuk analisa Big Data.
1. Kapan harus menggunakan Apache Druid
Druid digunakan untuk mendistribusikan sesuai dengan sekenario berikut:
· Pada saat proses Menambah data atau INSERT sangat tinggi, dan UPDATE data rendah.
· Kebanyakan menggunakan query untuk reporting seperti Grouping, tapi juga bias untuk query pencarian.
· Lama ekseskusi query antara 0.1 detik sampai beberapa detik.
· Data memiliki komponen waktu.
· Saat banyak sekali Table, tapi query hanya mengambil dari Table yang memiliki data yng Besar.
· Banyak kolom Cardinal (numeric) yang membutuhkaan perhitungan cepat dan melakukan pemeringkatan.
· Data yang akan di proses dari atau dalam bentuk Apache Kafka, HDFS, flat files dan Object Storage seperti Amazon S3.
2. Kapan tidak harus menggunanakan Apache Druid
Druid tidak bisa digunakan untuk mendistribusikan sesuai dengan sekenario berikut:
· Butuh waktu cepat untuk update Data. Druid mendukung untuk Streaming INSERT tapi tidak mendukung Streaimng UPDATE (bisa melakukan update tapi harus menggunakan batchs job dan memakan resource tentunya).
· Menyediakan reporting historical data dalam bentuk data mentah, tanpa adanya grouping.
· Membuat reporting system secara offline menghiraukan kecepatan proses data.
· Query yang memiliki join antara Big Table, yang mana kamu nyaman dengan query yang memakan waktu yang lama.
3. Integration
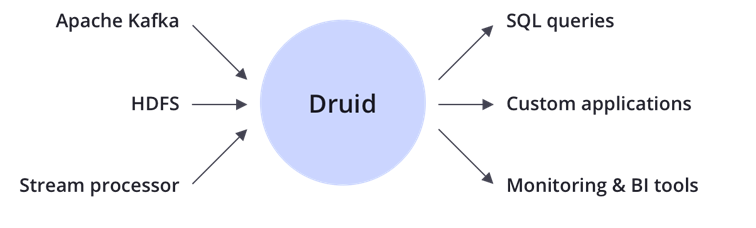
Druid bisaa digunakan beberapa opensource untuk terintegrasi diantaranya Apache Kafka, HDFS, System processor, dan kemudian out put dari integrasi Apache Druid diantaranya SQL Queries, Custom Aplications dan Monitoring & BI Tools.
4. Ingestion
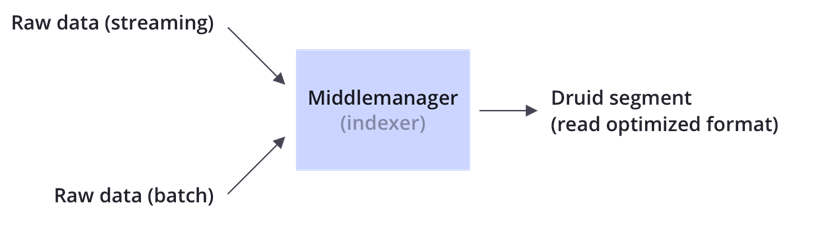
Druid mengolah data dalam bentuk Row Data hasil dari Event Streaming dan Barch File yang kemudian diolah sesuai dengan Spec dan akan menghasil kan druid segment yang bisa dugunakan. Bisa dilihat di dokumentasi: Link
5. Storage
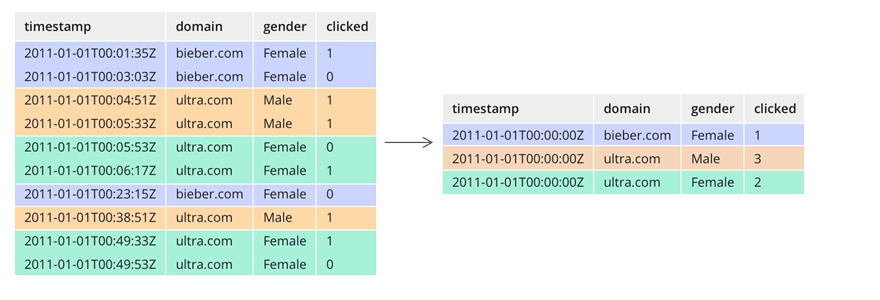
Seperti Data Store lainnya, Druid memiliki Colomn, data type (String, Num dll) dan tentunya druid menyediakan data partition berdasarkan waktu ingestion dari segment. Optimized Filter atau Query bisa di lakukan pada saat Proses Ingestion / Input Row Data.
bisa dilihat dokumentasi: Link
6. Querying
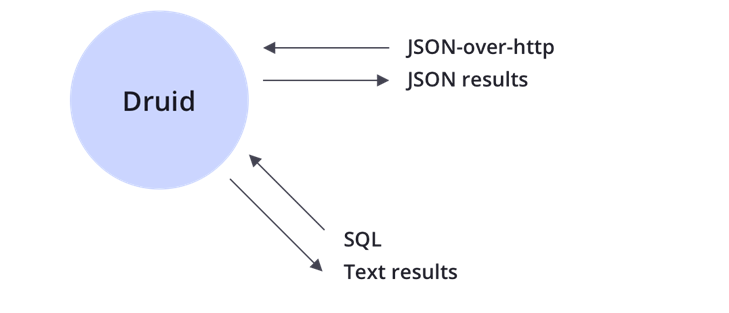
Querying dalam Druid bisa menggunakan JSON dan SQL, untuk SQL sepenuhnya querying akan sama dengan SQL seperti JOIN, GROUPING dll dalam bentuk aggregation. Silakan lihat dokumentasi: Link
7. Architecture
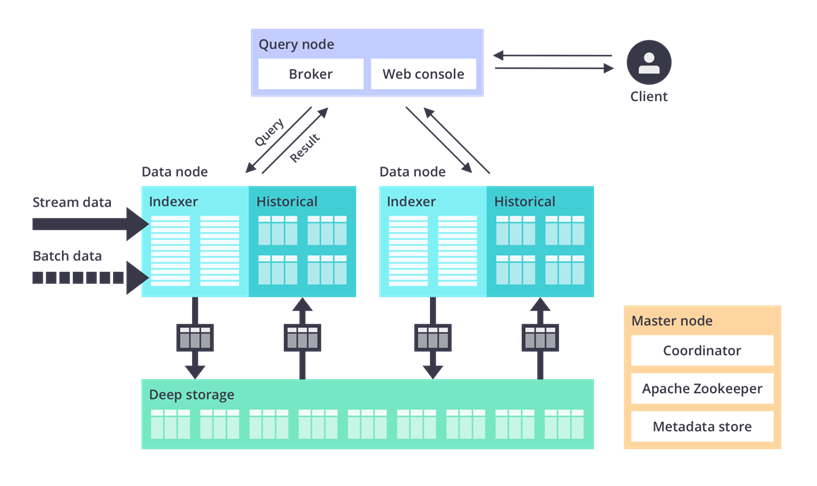
Druid memiliki Architecture seperti Figure 6, berikut runtutan penjelasannya:
· Raw Data (Stream Data/Batch Data) : Dalam bentuk Event Streaming atau dalam bentuk file (JSON, csv, txt dll).
· Data Node: Dalam data node terjadi Ingestion dengan indexer dan olah data untuk menjadi history Segment.
· Deep Storage: Dalam Deep Storage adalah data yang sudah di Ingestion akan tersimpan dalam Storage Druid dan data siap digunakan .
· Query Node: dalam query node ini adalah proses untuk mengambil data dan proses akhir analisa yang dibutuhkan.
B. Penggunaan Apache Druid
Dalam penggunaan Apache Druid yang saya praktik kan hanya menggunakan Load data Batch File dalam bentuk CSV. Druid bisa realtime hanya bisa menggunakan Event Streamer yaitu Apache Kafka,Kinesis, HDFS, Amazon S3. Dalam riset ini saya menggunakan Raw Data Batch File
Kenapa tidak Riset menggunakan Apache Kafka:
· Setelah berdiskusi apabila harus install apache Kafka harus menambah RAM kurang lebih 8 GB.
· Harus riset tapa itu Apache Kafka.
· Apabila kebutuhan untuk optimization Time Load bisa menggunaakan Chace seperti Redis.
Methode Raw Data Batch File tidak akan bisa mendapatkan Data Realtime dan data terupdate, dikarenakan saya upload melalui overlord secara manual walaupun bisa kita buat sebuahh strategi update batch file disimpan dalam storage kemudian kita buat Task Spec Granularity update setiap beberapa menit akan mengabil data secara terus menerus.
Akhirnya kami memutuskan untuk Riset menggunakan Batch File Load data dari storage. Dikarenakan Percobaan Batch File 4 Juta data gagal maka saya punya ide untuk partial dibagi per 200 Ribu. Dalam percobaan Load data dengan 4 Juta data saya mengalami permasalahan yaitu Pada saat Ingestion dimana Status akan selalu ‘WAITING’ dan apabila saya kill Task Ingestion maka akan hilang namun pada saat Load data lagi maka akan GAGAL seperti Figure 7. Akhirnya Harus install Ulang Apache Druid dan saya mencoba method maksimal Load data 200 Ribu dan setting Append sehingga data bisa menambah.
1. Load Data
Proses Load data ini bertujuan untuk menentukan proses Raw data yang akan diinputkan menggunakan method apa dan pengatusan Spec. Berikut Proses Load Data.
· Pilih Menu Load Data yang berada paling kiri Atas, dapat dilihat di Figure 8.
· Start: Pilih Menu Local Disk kemudian pilih Connect.
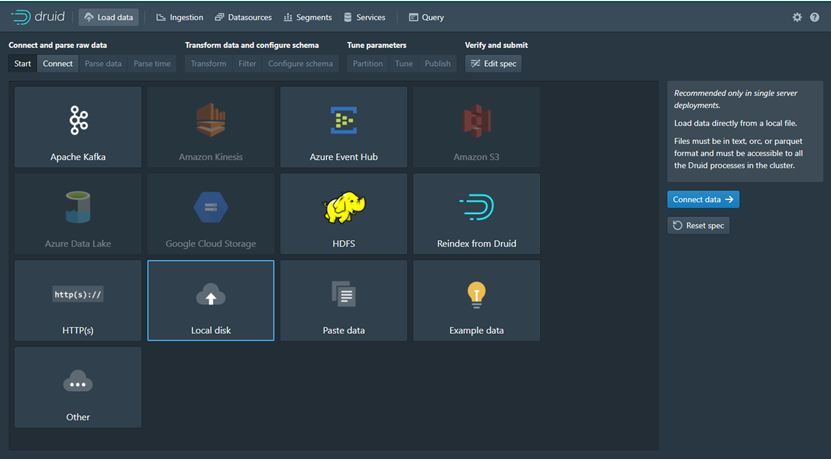
· Connect: Masukan informasi Source Type, Base Directory dan nama file csv. Kemudian klik Applyy dan kemudian file akan terload di Raw Data.
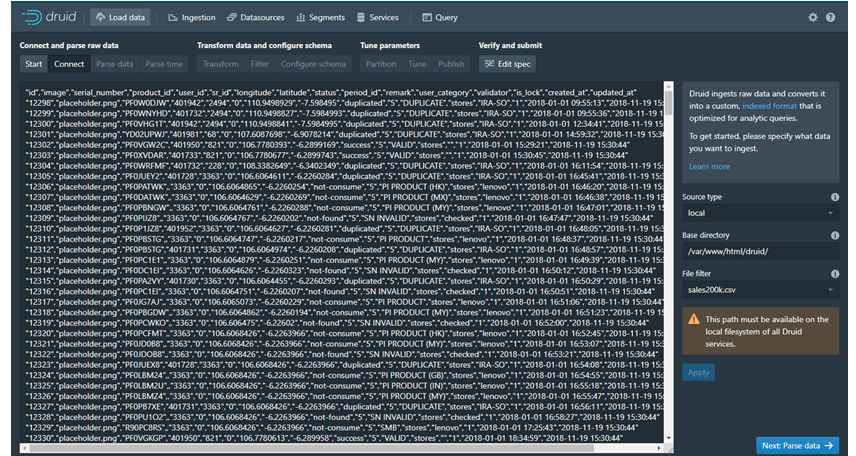
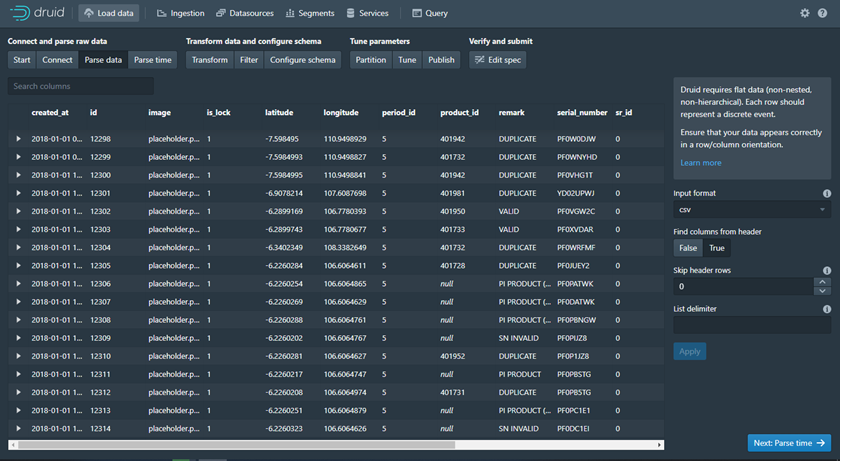
· Parse Data: Parsing data sebelum diolah di Parse Time, Parsing jenis data Raw Data yaitu Input Format (jenis format yang diinputkan),Find Colomn Fron Header (semacam filter dalam field apabila false akan ada permintaan nama colomn yang dihindari untuk di cari).
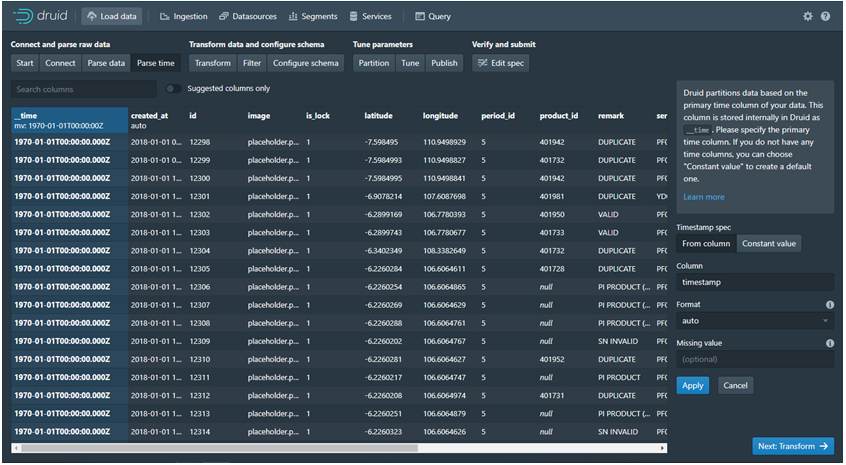
· Parse Time: Druid akan selalu berbasi skan waktu untuk mengolah data, sehingga dafult aka nada file bernama ( _time ) yang mengambil dari salah satu filed asli disini mengambil dari created_at . Dalam Parse Time kita bisa mengatur Timestamp bisa From Colomn ( dari colomn) atau bisa diisi sendiri (Constant Value).
· Transform: Dalam Transform Colomn lebih semacar Grouping dll dan bisa juga untuk alter field/Colomn.
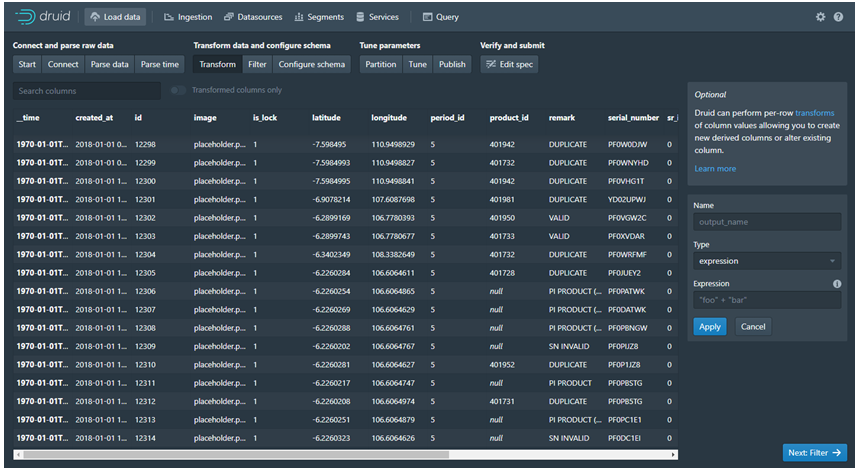
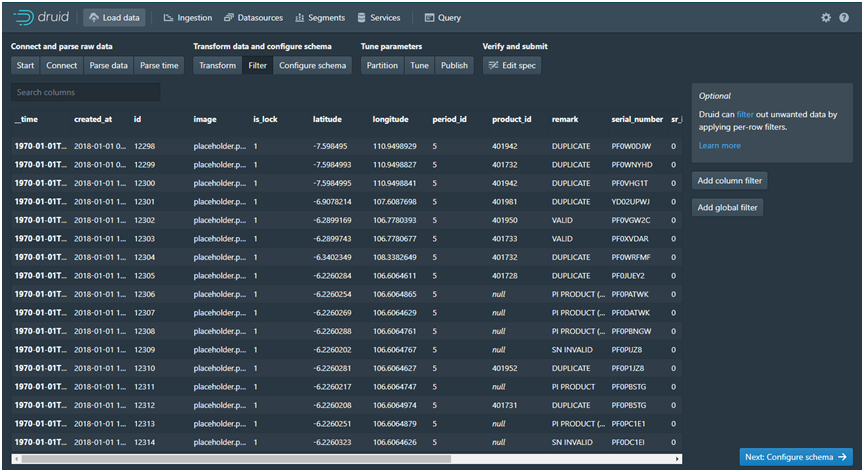
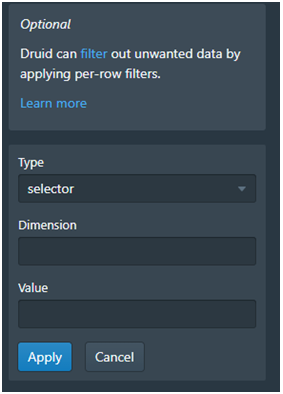
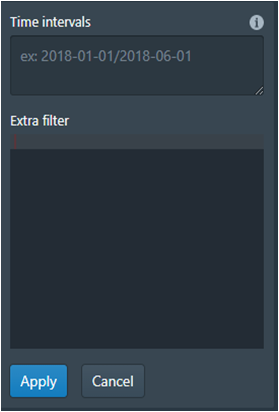
· Filter: Dalam Filter bisa memilih Add Colomn Filter dan Add global Filter seperti di Figure 14. Dalam Add Colomn Filter (Figure 15) ada Type filter, Dimension dan Value ini sama dengan di SQL type seperti SELECT Dimension seperti nama field dan value. Untuk Add Global Filter (Figure 16) bisa set Intervals dan Filter dalam Bentuk HJSON.
· Configure Schema: dalam Configure Schema ini ada untuk membuat liast Aggregation sesuai dengan type data.Terdapat Add Dimension bisa untuk menambah Field dan Add Metric untuk menambah Schema perhitungan di Filed Baru. Dan Set Granularity yaitu Setting Query akan diupdate setiap Waktu tertentu atau juga bisa tidak diatur.
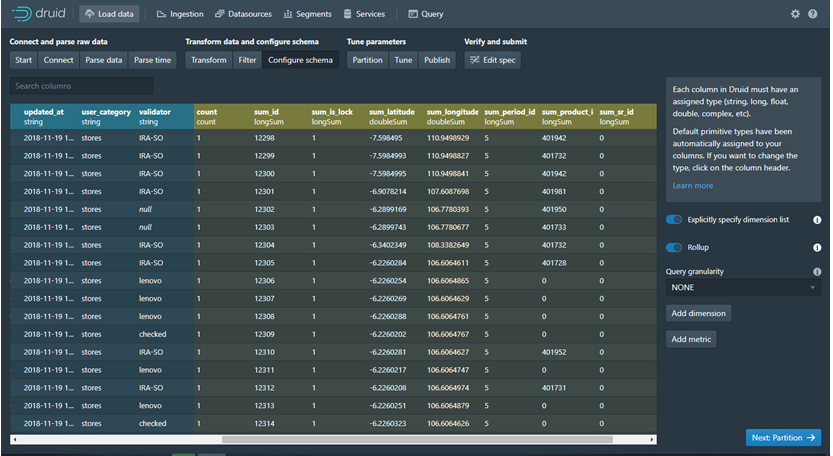
· Partition: Dalam Partition ada beberapa Fitur namun fitur utama nya adalah Partition By Time dan Secondary Partition, kebetulan disini saya setting Type Uniform dan segment granularity By HOUR selebihnya default dari Druid Learn More.
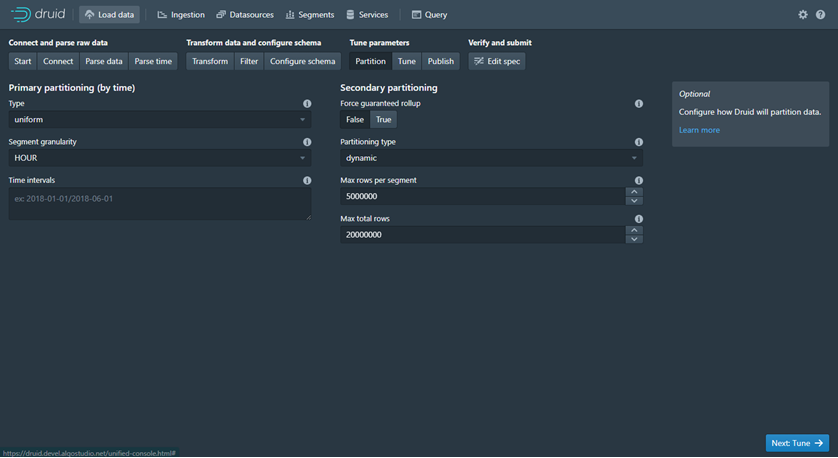
· Tune: Disini untuk mengatur properties dari Ingestion data untuk men setting kecepatan memory task dll. Learn More
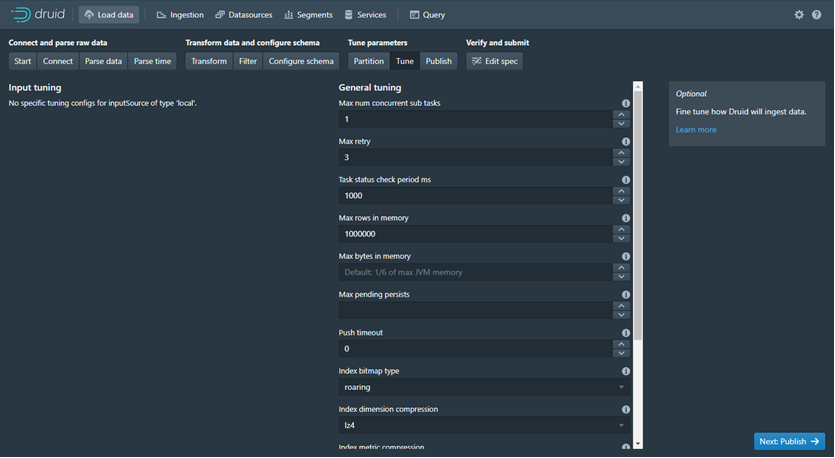
· Publish: dalam publish terdapat configurasi Datasource Name atau istilahnya dalah SQL Table Name, dn kemudian bisa di Append data apabila terjadi Task berulang maka data akan menambah dan tidak di rebase. Parse Error untuk menyimpan setiap Log Error pada saat menjalankan Task.
· Edit Spec: Spec adalah ringkasa dari semua Configurasi muli dari Start sampai Publish yng di simpan dalam bentuk JSON. Apabilasudah mkaa siap Untuk Di submit dan masuk ke Task Ingestion.
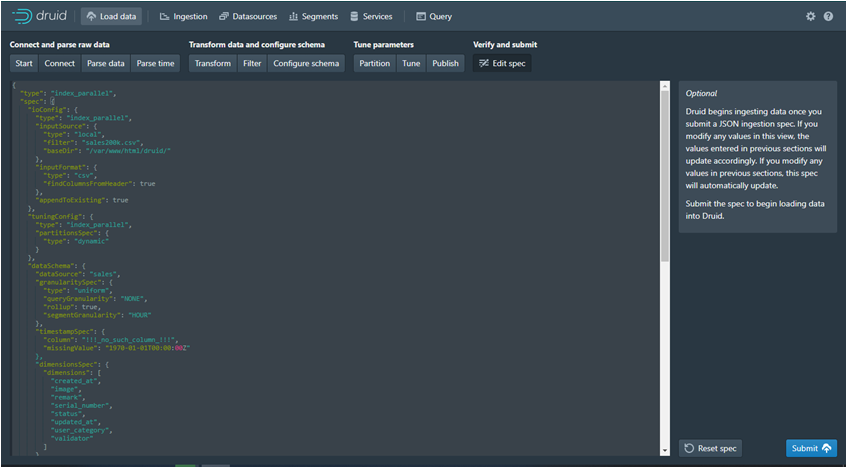
2. Ingestion
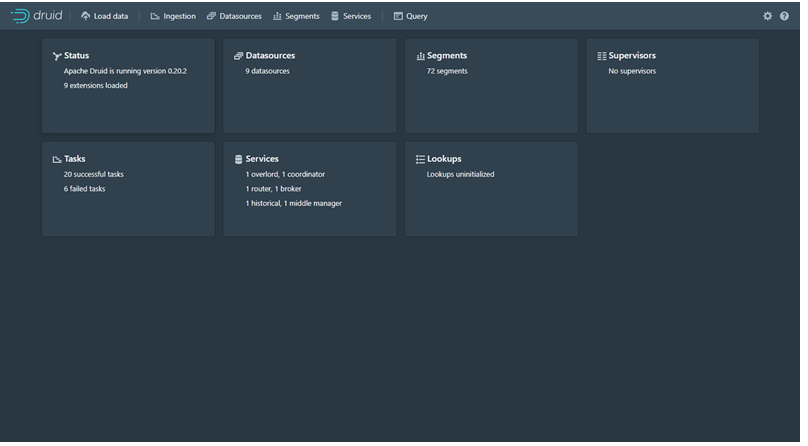
Menu Ingestion ada 2 Fitur yaitu Untuk Supervisor dan Tasks yang mana untuk memperlihatkan proses Ingestion yang terjadi di Overlord Learn More. Beberapa Status dalam Task Ingestion:
· RUNNING : menunjukan proses Task ingestion dalam proses (Figure 22)
· PENDING: Menunjukan harus menunggu Task yang running menjadi tidak success.
· FAILED: Apabila Task memiliki Spec yang tidak valid seperti Raw Data yg sebenaarnya tidak ada.
· WAITING: Waiting terjadi pada saat menunggu proses Deep Storage dari system belum selesai.
· SUCCESS: Sukses adalah proses yang menunjukan Task sudah selesai dan Data source, service, Segment dan Query sudah terbuat dan bisa digunakan.
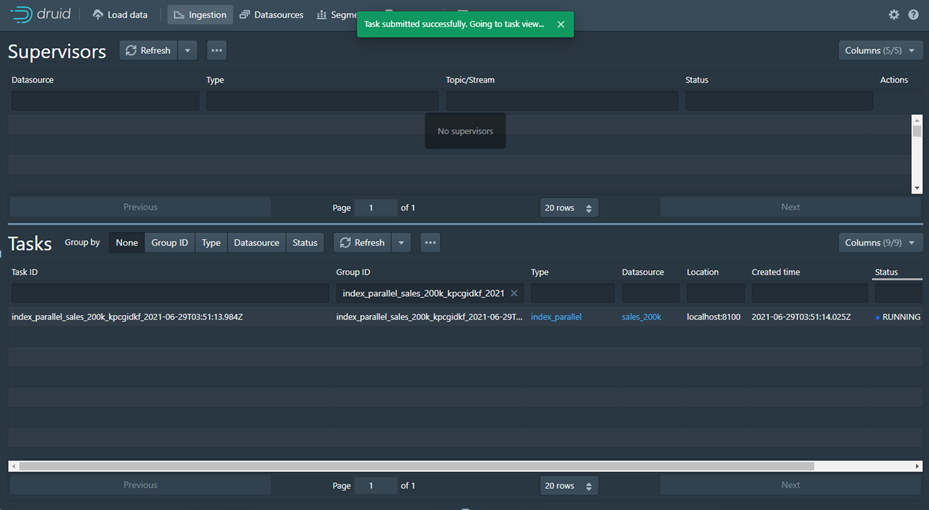
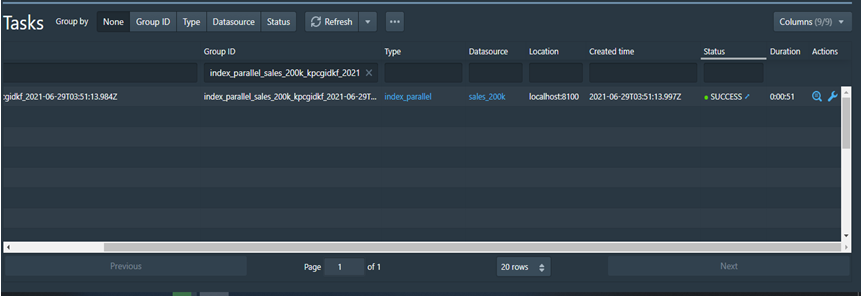
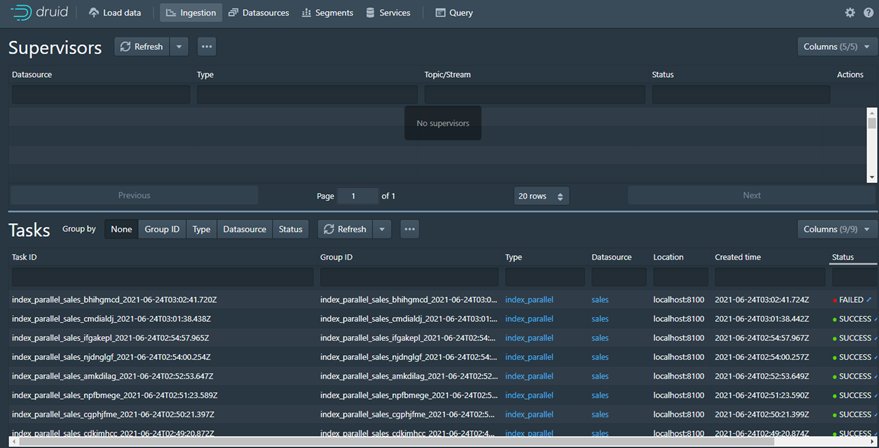
3. Data Source
Dalam data source akan terlihat list nya dan mana yg aktif atau pun tidak dan beberapa field yang menunjukan informasi Datasource.
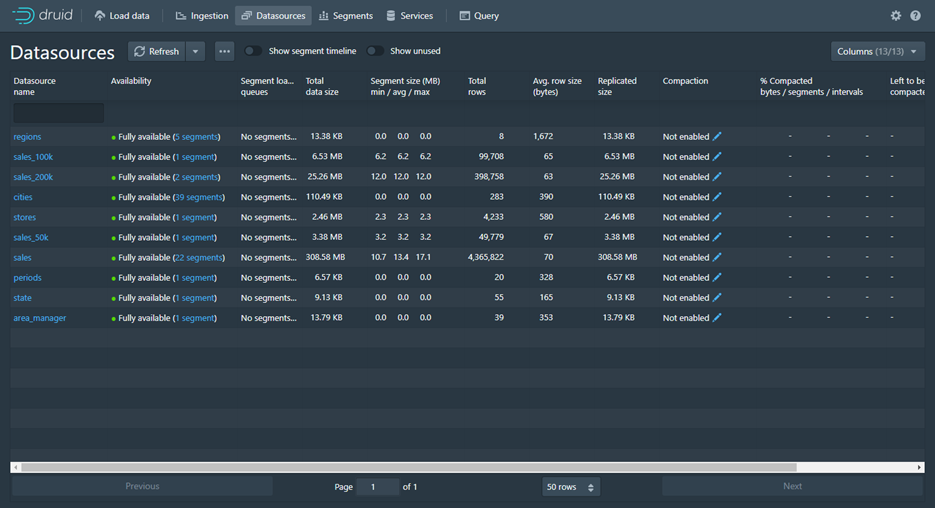
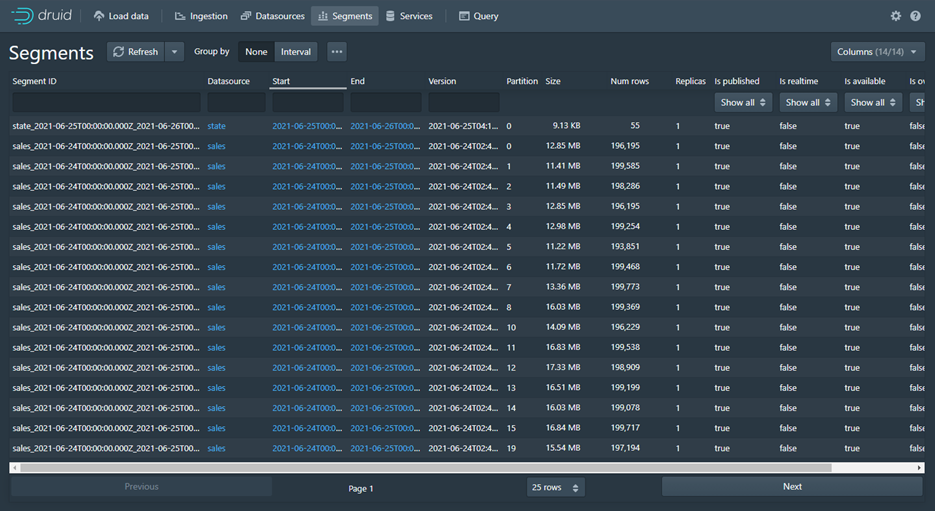
4. Segments
Dalam segment terdapat informasi hasil ingestion yang dibuat dalam bentuk segment.
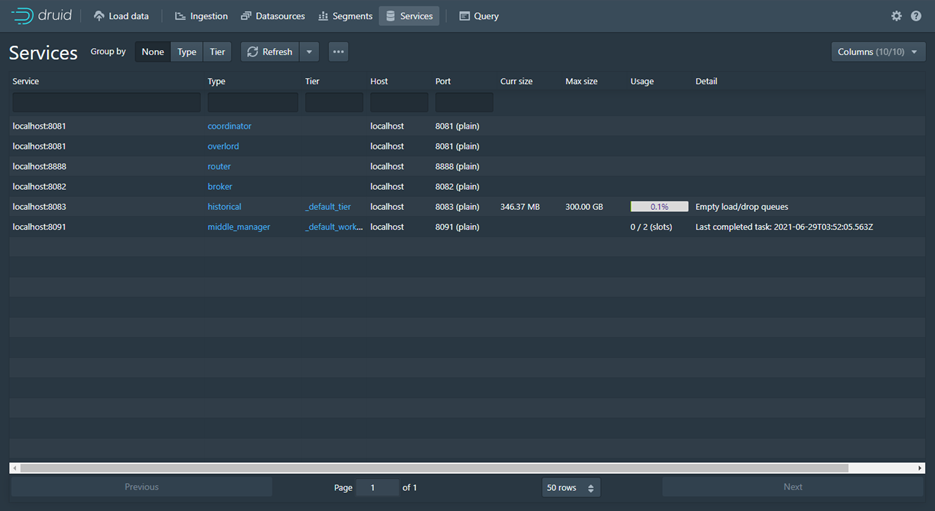
5. Services
Service menunjukan informasi service PoRT yang berjalan dan Informasi Max Sice Usage daan Detail.
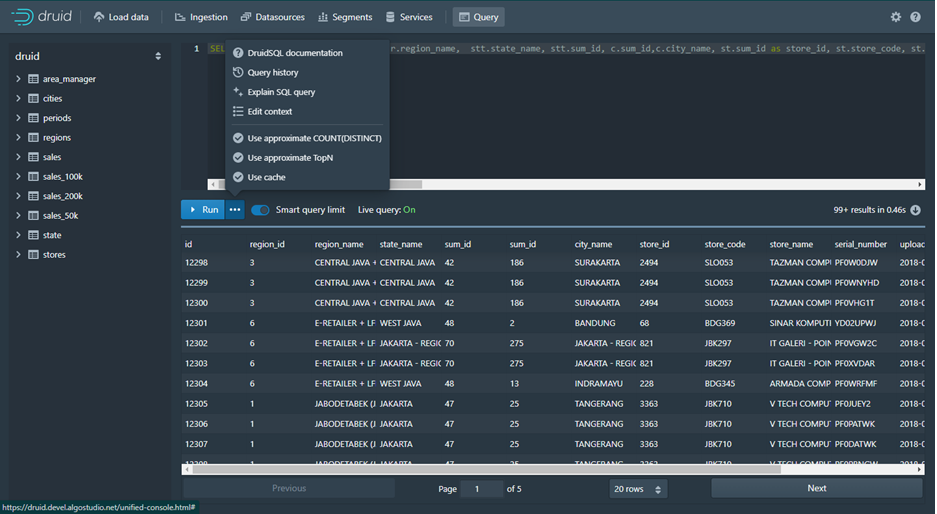
6. Query
Querying dalam Apache Druid bisa dibuat dalam bentuk Model MYSQL juga bisa dalam Bentuk JSON. Ada beberapa property yang bisa dugunakan didalam druid bisa dipelajari disini Learn More
C. Queries Library
Depedensi Library yang bisa digunakan untuk Fetch atu olah Query Apache Druid terdaapat hampir disemua Platform dan Bahasa Pemrograman silahkan kunjungi Learn More.
A. Benchmark Performance
Dalam Benchmark ini saya membandingkan Performa dengan Druid dengan MYSQL dan Query Service HTTP (API Druid) Dengan MYSQL. Dengan menggunakan schema Querying di Druid dan di MYSQL. Sebelumnya ada beberapa langkah dalam ingestion yang saya buat default saya sesuaikan agar bisa Load Data sebanyak 4 Juta data. Berikut List Datasource yang bisa kita gunakan Figure 30.
Mengesampingkan spesifikasi Server disini saya akan mencoba membandikan Druid Query dengan MYSQL Query dan Service HTTP (API Druid) dengan MYSQL Query untuk mendapatkan performa secara latency time. Disini kita menggunakan Query yang sama dengan jumlah data yang sama sebagai Acuan.
Proses Cara Perbandingan:
· Druid Query
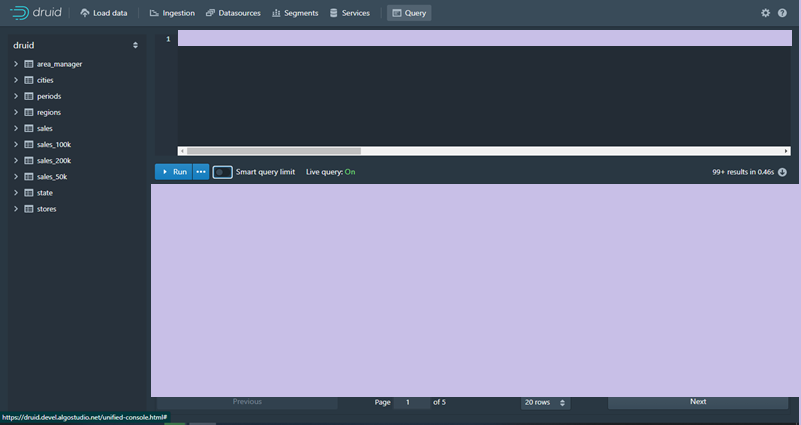
Dalam Console Druid saya akan membuat Query dan kemudian saya menghilangkan Smart Query Limit untuk menghilangkan fitur limit sehingga akan diload semua sesuai dengan Query yang sama.
· MYSQL Query
Dalam MYSQL Query saya menggunakan HEIDISQL.
· Service Druid (API Druid).
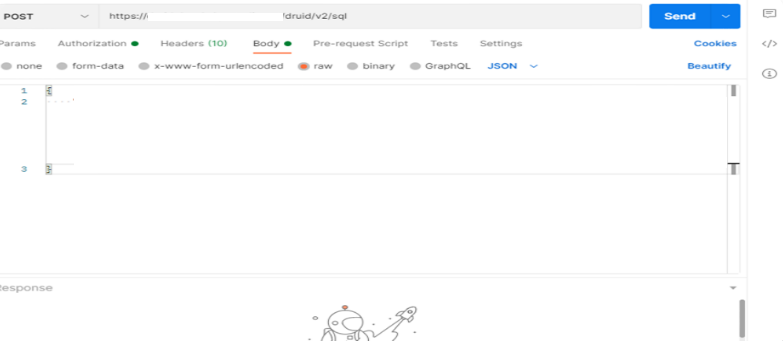
Dalam Service ini saya menggunakan POSTMAN sebagai Tools untuk Client Service HTTP.
Saya harus setting sebagai berikut
i. Authorization: menggunakan Basic Auth
ii. Header : KEY: Content-Type Value : application/json
iii. End Point: https://linkendpoint/druid/v2/sql
iv. Request rody: raw JSON
Berikut hasil dari perbandingan performa :
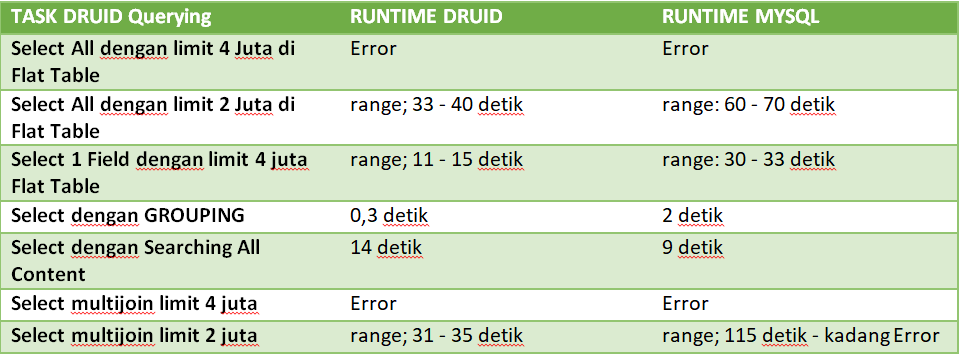
· Druid Query VS MYSQL Query
· Service HTTP (API Druid) dengan MYSQL Query
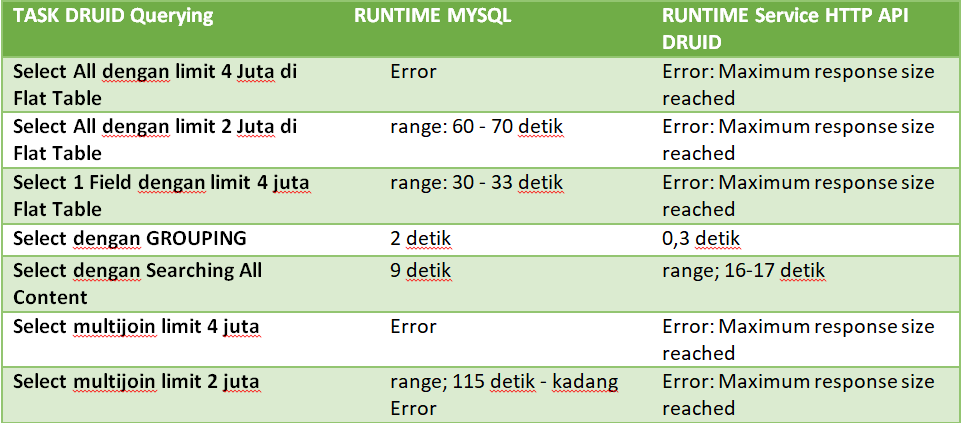
Dari perbandingan Druid dengan MYSQL berdasarkan lama latency load data terdapat beberapa hasil sebagai berikut:
1. Untuk Pencarian dengan sepesifik field dan filter Druid bisa lebih cepat 2 kali lipat bahkan lebih Query Biasa melalui MYSQL.
2. Untuk Pencarian Flat Table Serrch All Content pakai OR Query maka MYSQL Query bisa lebih cepat hampir 2 kali lipat.
3. Untuk mengambil data Flat table dan multi join sebanyak 4 Juta Data terjadi Error.
4. Untuk Service HTTP API Druid akan mengalami Error response size apabila memasuki data berjuta, selama masih belum masuk berjuta masih Aman.