Heroku adalah layanan cloud yang memungkinkan developer untuk mendeploy, mengatur dan memonitor aplikasi tanpa mengurus kerumitan masalah infrastruktur. Heroku sangat cocok bagi developer atau startup yang ingin menguji produknya karena proses build & deploynya sangat mudah dan murah karena ada paket harga yang gratis (dengan limit tertentu).
Dengan segala kemudahan yang ditawarkan oleh Heroku, akan tetapi Bahasa pemrograman yang disupport tidak terlalu banyak. C# dan ASP .Net Core adalah salah satu yang tidak disupport. Namun tidak usah khawatir, karena Heroku juga memberikan opsi melalui third-party buildpack untuk mengatasi hal itu. Lalu gimana caranya kita sebagai developer .Net jika ingin menggunakan layanan dari Heroku? Berikut step-step nya:
Dalam pengembangan aplikasi tentunya kita membutuhkan storage untuk menyimpan berbagai file, dalam pengembangan aplikasi yang sudah berskala besar tentunya kita mempertimbangkan untuk memisahkan penyimpanan dengan source kode aplikasi ini yang dinamakan stateless application yang mana kita bisa menggunakan beberapa server untuk satu aplikasi
Nah salah satu object storage ini adalah Digital Ocean Space yang mana menjadi kompetitornya Amazon S3, DO Space sendiri adalah layanan penyimpanan objek yang kompatibel dengan API Amazon S3. DO Spaces menyertakan CDN terintegrasi yang dapat Anda aktifkan tanpa biaya tambahan.
Menulis kode yang rapi, terstruktur dan menggunakan standard yang telah ditetapkan akan memudahkan kita seorang developer untuk melakukanperawatan project yang sudah kita buat, tidak hanya saat proses pengembangan, namun juga dalam proses perawatan dalam jangka waktu yang panjang, apalagi untuk project yang sudah bersekala besar, sangat kompleks dan di maintain oleh banyak developer.
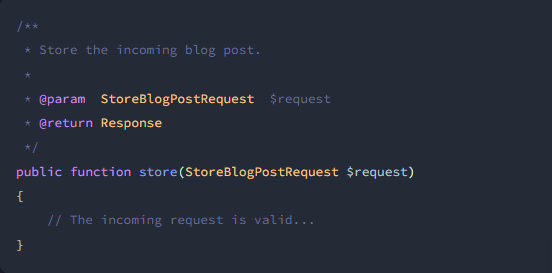
Terdapat salah satu fitur yang bagus pada framework laravel, yaitu Form Request, fitur ini merupakan sebuah kelas yang bertugas hanya untuk melakukan validasi dari setiap inputan yang masuk sebelum di olah, jadi fitur ini memungkinkan kita untuk memisahkan proses pengecekan / validasi dengan proses bisnis, sehingga kode yang kita tulis tidak tercampur menjadi satu file
kita pasti seringkali menggunakan Intent untuk navigasi antar activity di aplikasi, kita juga sering menggunakan fragmentManager untuk transaksi antar fragment. cara-cara itu memerlukan berbaris-baris kode apalagi jika terdapat konfigurasi lain seperti penambahan Extras atau penambahan animasi. selain itu navigasi nya juga tidak terstruktur sehingga kita terkadang bingung dengan alur navigasi di Aplikasi kita.
Pengembangan software yang kompleks tidak terlepas dari database yang kompleks pula, terdiri dari beberapa tabel yang berkesinambungan dan memiliki relasi satu sama lain, dalam dokumentasinya mysql di sebutkan seperti ini
By default, MySQL runs with autocommit mode enabled. This means that, when not otherwise inside a transaction, each statement is atomic, as if it were surrounded by START TRANSACTION and COMMIT. You cannot use ROLLBACK to undo the effect; however, if an error occurs during statement execution, the statement is rolled back.
secara default mysql berjalan dengan autocommit yang sudah diaktifkan, jadi setiap query akan dijalankan sesuai order namun jika ternyata di tengah tengah proses terjadi sesuatu error, yang mungkin bisa jadi disebabkan oleh terputusnya koneksi user atau karena hal lain, maka query yang sudah tereksekusi di awal tidak akan bisa dilakukan mekanisme rollback, maka dari itu diperlukan mekanisme database transaction, agar setiap rangkaian query yang kita harapkan jika terjadi kesalahan di tengah tengah maka proses dari awal dapat dibatalkan
Dalam membuat aplikasi, kita pasti akan menguji aplikasi nya apakah ada error atau bug pada kode yang kita tuliskan. Pasti kita butuh berkali-kali melakukan pengujian aplikasi baru bisa bebas dari error atau bug, yang berarti kita harus menjalankan berkali-kali prosedur pengujian. akan cukup melelahkan jika kita melakukan pengujian secara manual dan bisa juga ada pengujian yang terlewatkan. Sebenarnya ada fitur pengujian otomatis di Android yang bernama Instrumentation Testing atau UI Testing, fitur yang memungkinkan kita melakukan pengujian secara otomatis pada aplikasi secara berurutan berdasarkan perintah yang kita berikan. namun kita perlu belajar perintah-perintah pengujiannya untuk dapat menggunakan Instrumentation Testing dan tentunya kita perlu melakukan koding lagi untuk membuat pengujian. cukup melelahkan bagi beberapa orang karena harus ngoding lagi.
Microservices adalah arsitektur yang digunakan untuk mengembangkan system yang dibagi menjadi bagian-bagian kecil / modular dan memungkinkan teknologi yang digunakan berbeda sesuai kebutuhan dan kemudahan dalam satu system. Di dalam microservices memungkinkan setiap fitur dikembangkan dengan teknologi yang berbeda baik dari skema Database ataupun Bahasa Pemrograman. Microservices sering digunakan oleh pada system produk yang memiliki skala yang besar, kompleksitas dan transfer rate yg sangat besar.
Diketahui aplikasi yang menggunakan Microservices Gojek, Grab, Tokopedia, Shopee, Paypal , Twitter, Netflix dan lain lain.
SwiftUI ialah framework UI baru yang dikenal oleh apple semenjak iOS 13 pada WWDC2019. SwiftUI ini sendiri bersifat deklaratif sehingga gampang sekali untuk membuat UI dengan framework ini. Selain itu SwiftUI juga memiliki fitur yang sangat menarik yaitu kemampuan untuk MultiPlatform, yaitu sekali coding SwiftUI mampu berjalan di iPhone, iPad, MacOS serta AppleWatch.
Menurut saya sendiri, SwiftUI akan semakin banyak digunakan oleh developer yang ada di dunia. Pada WWDC kemarin sendiri, weather app pada iOS 15 sudah ditulis ulang menggunakan SwiftUI sendiri. Hal ini memungkinkan bahwa SwiftUI cukup stable untuk dilanjutkan pada tahap production.
Ayo kita telusuri SwiftUI bersama-sama
Hands On
Pada artikel ini kita akan mencoba membuat sebuah aplikasi list contact sederhana untuk mendemontrasikan seberapa gampang membuat UI dengan framework ini sendiri.
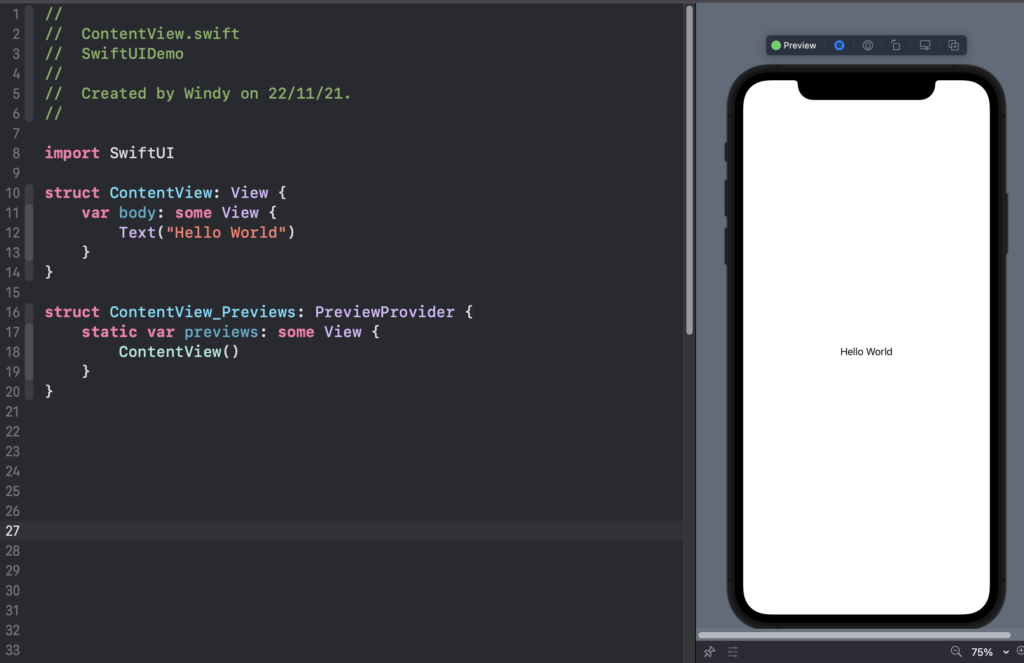
Ini merupakan template default dari SwiftUI sendiri, pada SwiftUI kita sudah tidak mengenal Storyboard hahaha. Kodingan yang diperlukan untuk membuat UI akan kita tulis pada bagian body.
Default Template
Prepare Dummy Data
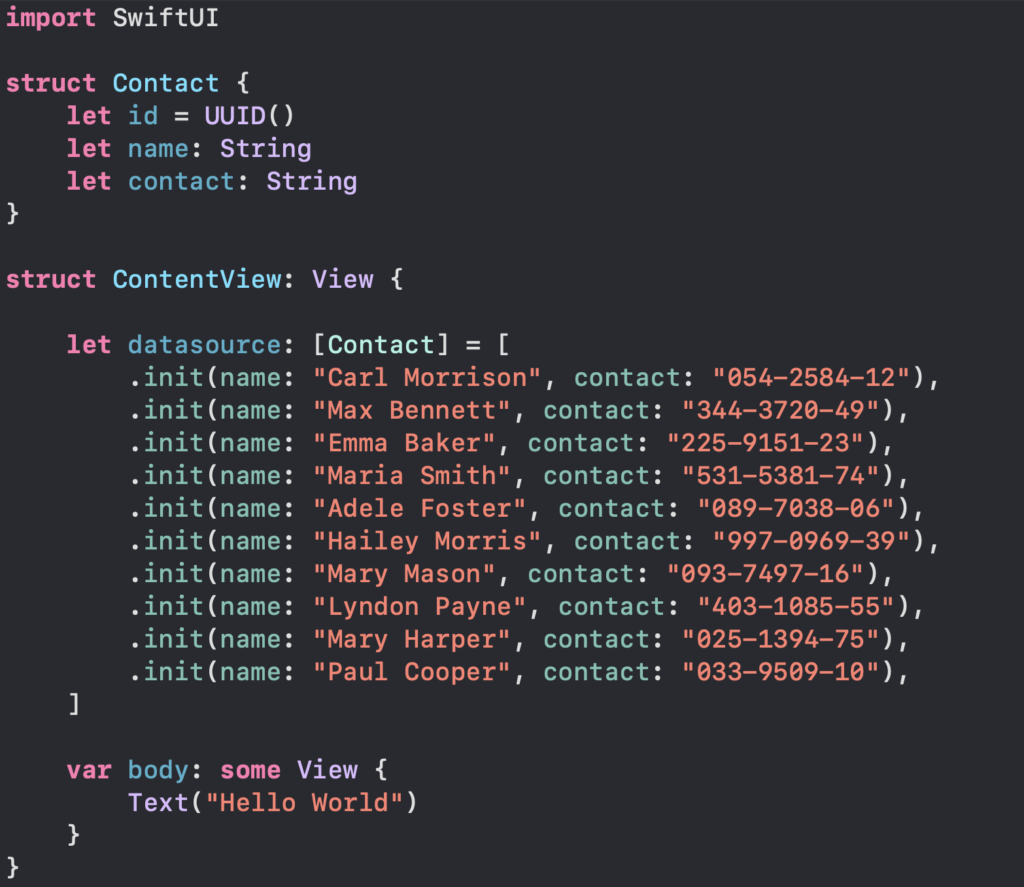
Ayo kita menyiapkan dummy data kita seperti ini
Dummy Data
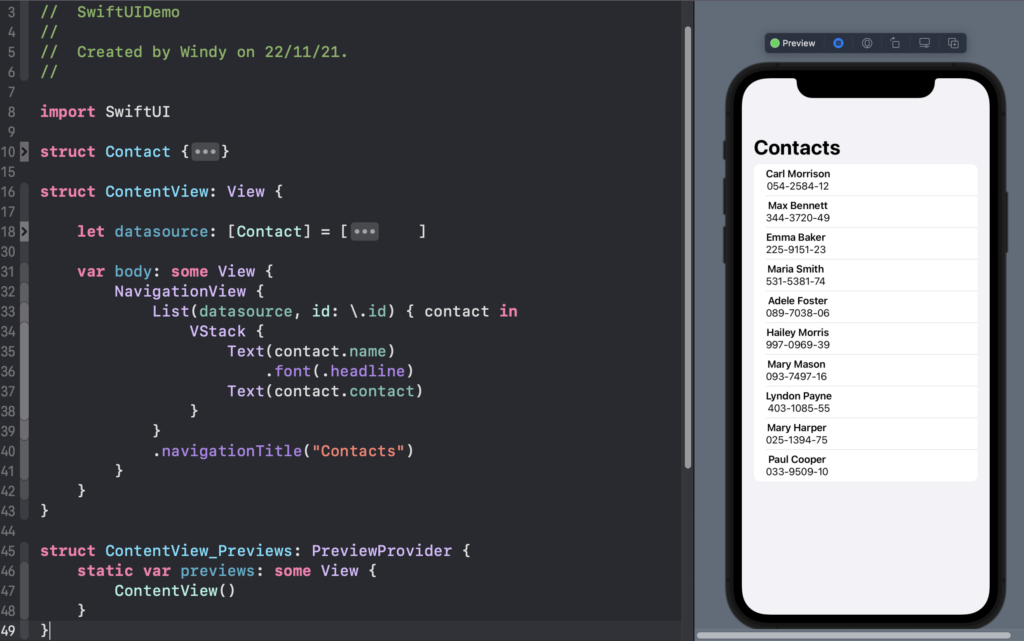
Membuat List
Bahkan untuk membuat tampilan list sederhana kita hanya perlu kode kurang dari 10 baris
List
Hanya dengan beberapa baris kode, kita sudah dapat membuat UI dengan sangat gampang. Apabila kita menggunakan UIKit, maka teman-teman sudah bisa menebaknya. Kita harus melakukan setup dengan UITableViewDataSource dan UITableViewDelegate kemudian kita juga perlu membuat tableviewcell serta kita juga perlu berurusan dengan autolayout.
Kesimpulan
Semoga dengan contoh seperti ini dapat memberikan gambaran seberapa powerful SwiftUI ini. Walaupun SwiftUI ini sendiri belum akan digunakan pada waktu yang dekat, namun SwiftUI ini sendiri dapat menjadi investasi yang baik untuk masa depan. Berikut referensi video pertama kali SwiftUI diperkenalan pada WWDC2019.
Github mengeluarkan salah satu produknya AI yang sangat powerfull bernama GitHub Copilot, dengan tagline nya “Your AI Programmer” tools ini bisa memberikan suggestion kepada kita untuk menyelesaikan sebuah problem, hanya dengan mengetikkan sebuah komentar saja nantinya Github Copilot ini dapat memberikan sampai sepuluh rekomendasi, bahkan untuk dapat menyelesaikan algoritma struktur daya yang rumit sekalipun, untuk support bahasa pemrogramannya saya mengutip di websitenya begini
“GitHub Copilot works with a broad set of frameworks and languages. The technical preview does especially well for Python, JavaScript, TypeScript, Ruby, Java, and Go, but it understands dozens of languages and can help you find your way around almost anything.”
Karena untuk sekarang statusnya masih technical review, buat yang ingin menjadi tester GitHub Copilot ini dapat mengajukanya di https://copilot.github.com/ kurang lebih sekitar 4-5 bulan nanti akan mendapatkan email persetujuan dari GitHub seperti ini
Kita kadang butuh menyimpan data secara lokal untuk mempercepat load aplikasi dan menghemat bandwidth server. lalu bagaimana jika data yang kita simpan di lokal merupakan data yang penting dan sensitif ? kita memerlukan enkripsi untuk mengamankan data tersebut. user biasa memang tidak bisa mengakses file database di aplikasi kita, namun jika user tersebut tau bagaimana cara mendapatkan database nya maka semua data yang ada di database dapat dengan mudah terbaca karena tidak ada enkripsi yang dilakukan.