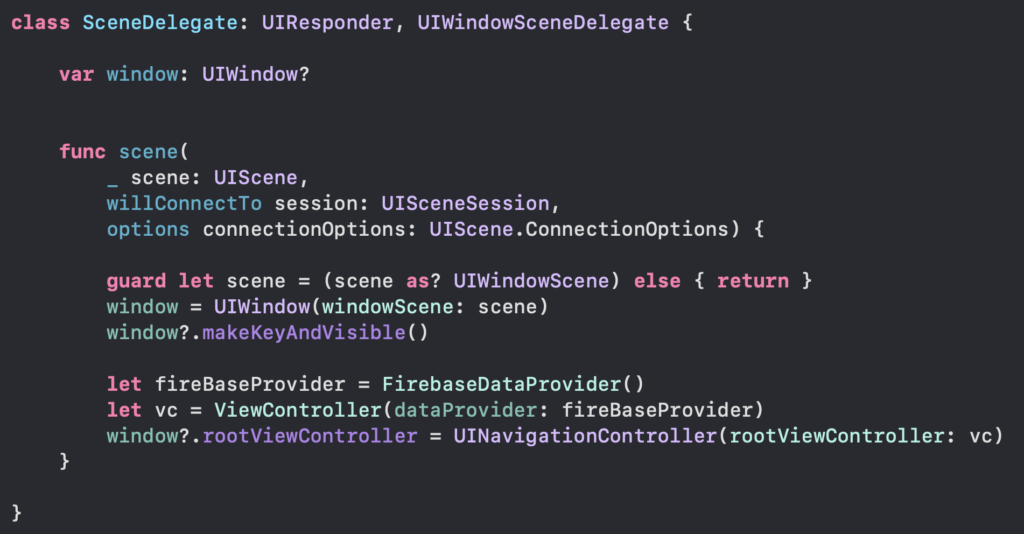
Dalam belakangan ini pattern yang lagi trend digunakan banyak instansi dalam membangun aplikasi baik android ataupun ios hal tersebut terbukti banyaknya recruitment yang membutuhkan spesifikasi dengan pattern MVVM. Nah MVVM itu bagaimana sih?
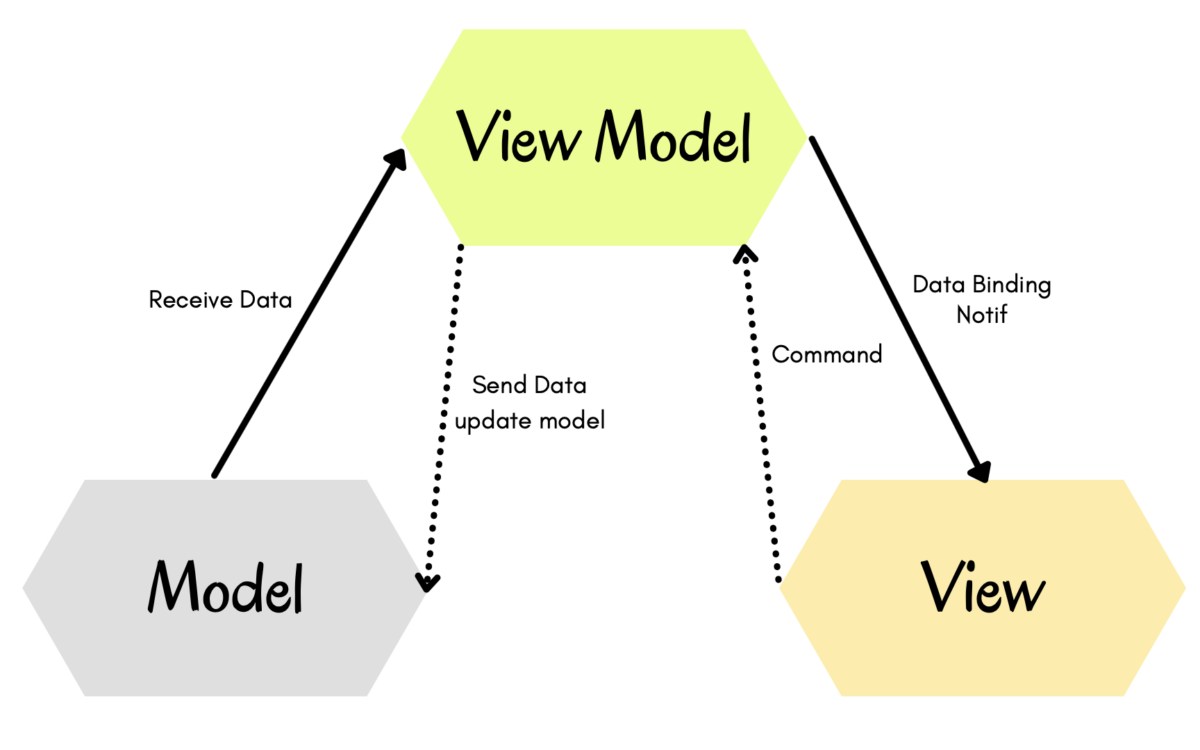
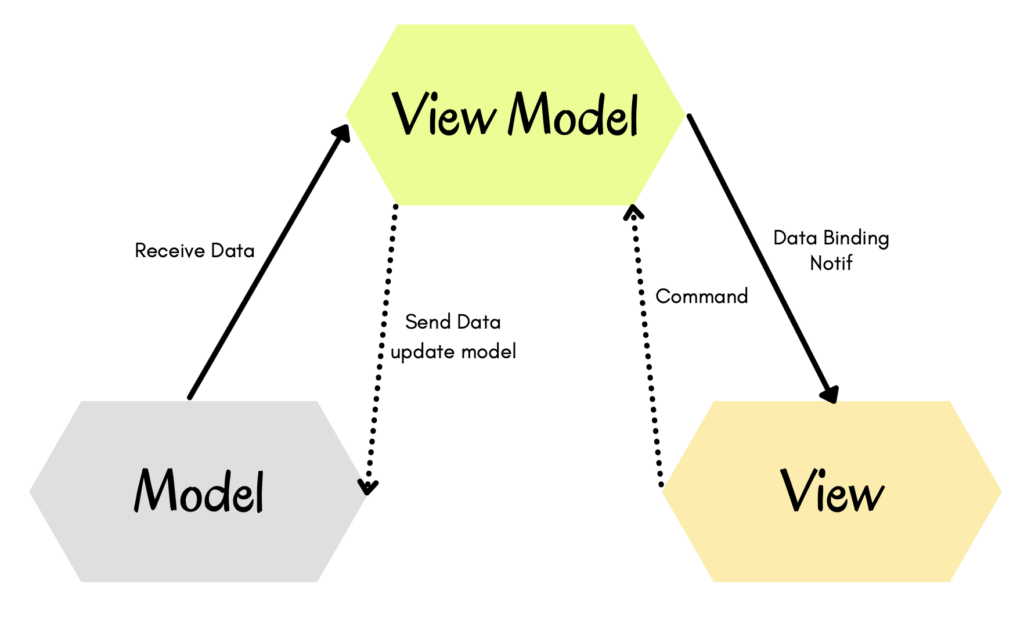
MVVM atau Model-View-ViewModel adalah sebuah Architetural Pattern dimana dia membagi tugas dan tanggung jawab kepada 3 komponen nya, yaitu Model, View, ViewModel (Wikipedia).
Model, merupakan sebuah wadah untuk menampung data-data yang telah didapatkan baik dari API maupun data yang dibuat secara local.
View, komponen yang bertanggung jawab kepada seluruh tampilan atau UI dalam Aplikasi kita baik UI dari programmatic, storyboard ataupun swiftui. Dan yang terakhir ada ViewModel yang merupakan inti dari Architecture Pattern ini, yaitu bertugas sebagai tempat komunikasi antara Model yang menyediakan data dengan View yang menampilkan data.
Kelebihan MVVM yang kerasa banget adalah code nya enak banget untuk dibuat unit testingnya dan reusable. Akan tetapi terdapat kekurangan juga bagi pemula akan kerasa sulit untuk membuat viewModel yang efektif. Untuk lebih jelasnya mari kita bedah langsung dengan membaca alur kode swift dengan pattern MVVM.
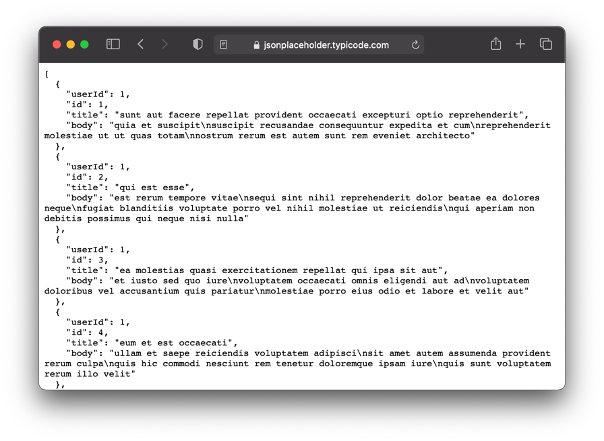
- Kita buat model dulu sesuai dengan api yang akan diakses, disini kita akan menggunakan api public dari https://jsonplaceholder.typicode.com dengan mengakses end point bagian post. Dimana balikan data dari api tersebut seperti berikut:
Sehingga kita buat modelnya menjadi:
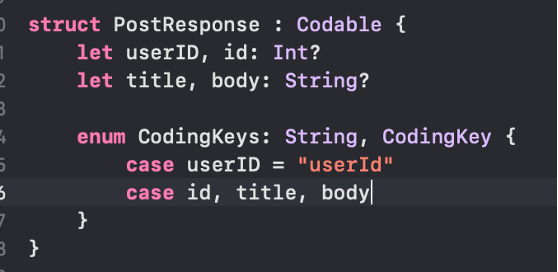
Jangan lupa kita menggunakan tanda tanya (?) sebagai upaya kalau seandainya terdapat nilai null dari response end point tersebut.
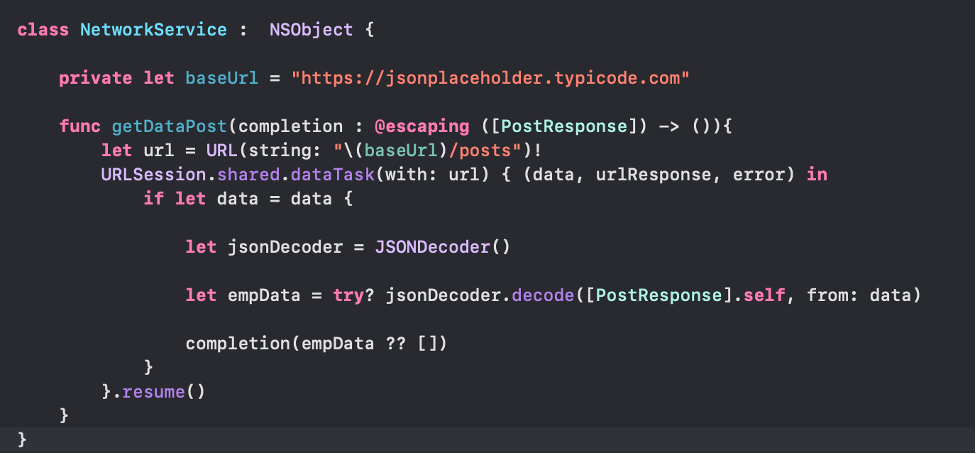
- Buat networkingnya, disini kita buat class terpisah agar lebih enak maintenancenya. Buat class NetworkService.swift dan buat balikan datanya sesuai dengan yang diperlukan, seperti completion: @escaping ([PostResponse]) yang berarti fungsi tersebut nantinya akan mengembalikan value berupa array data dalam model PostResponse. Data diperoleh dari API di decode menggunakan JSONDecoder.decode dimana data akan dimasukkan ke dalam modelnya.
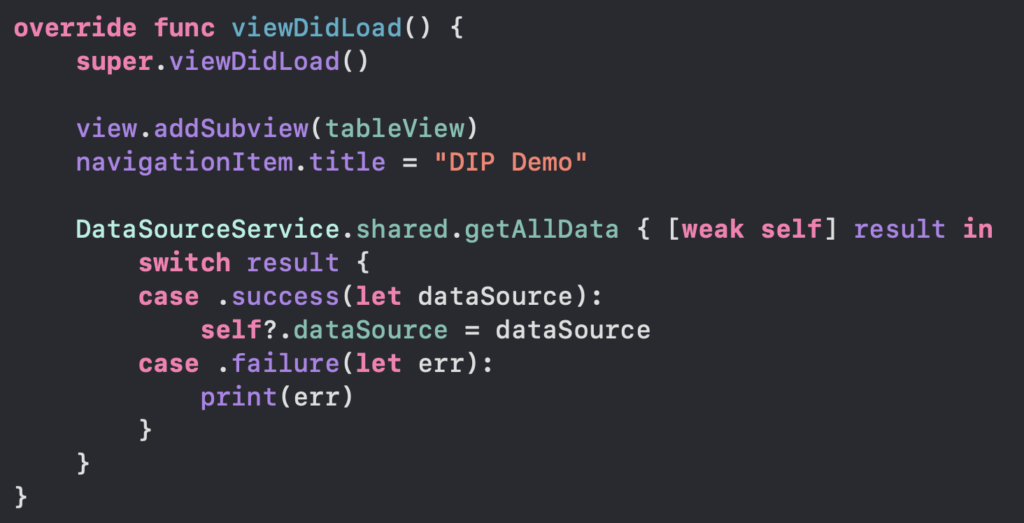
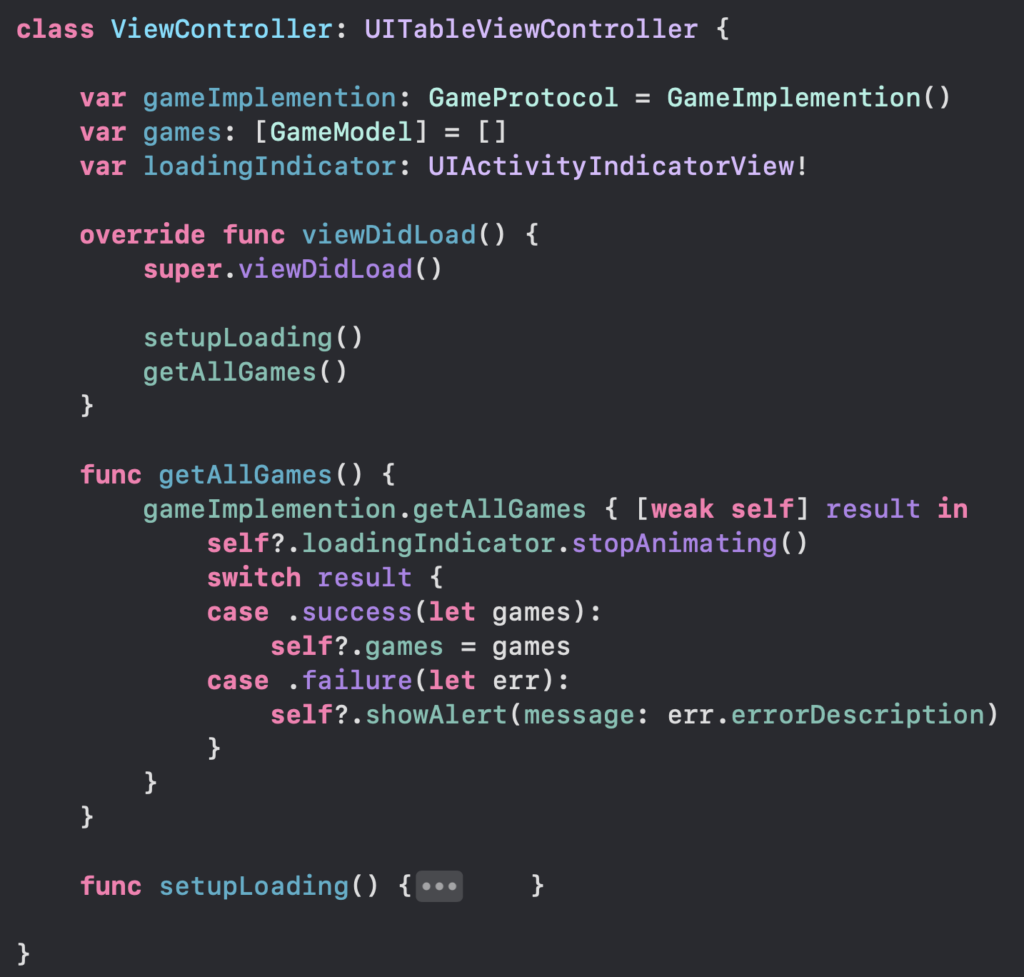
- Sekarang buat PostViewModel. Pada class ini berisi function untuk mengambil data dari function networking yang telah dibuat sebelumnya seperti gambar dibawah ini.
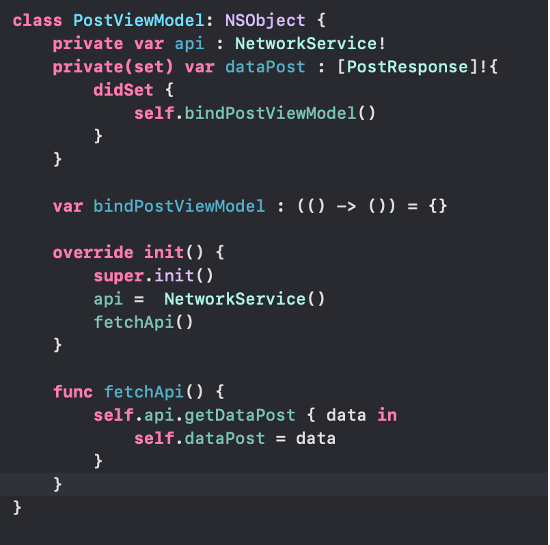
Pada code tersebut terdapat 3 variabel yang berbeda”, yaitu api, datapost dan bindPostViewModel. Variable api digunakan untuk memanggil class networkservice yang telah dibuat sebelumnya. Variable dataPost digunakan untuk menyimpan data dari api yang telah dipanggil melalui function fetchApi dan didalam dataPost terdapat didSet dimana setiap kali ada perubahan data maka akan mengirim notif ke view. Variable bindPostViewModel akan digunakan di View nya dan notif viewModel ke view melalui variable ini.
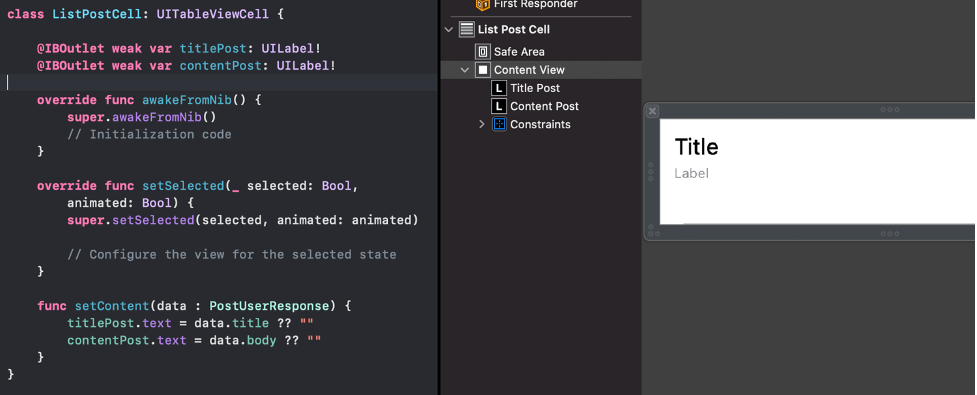
- Kita buat View, dimana kali ini menggunakan storyboard untuk interfacenya. Dalamnya hanya terdapat UITableView dan UITableViewCell di buat secara terpisah. Cell dari TableView dibuat seperti berikut ini.
- Kemudian kita setting dataSource untuk tableView seperti berikut ini.
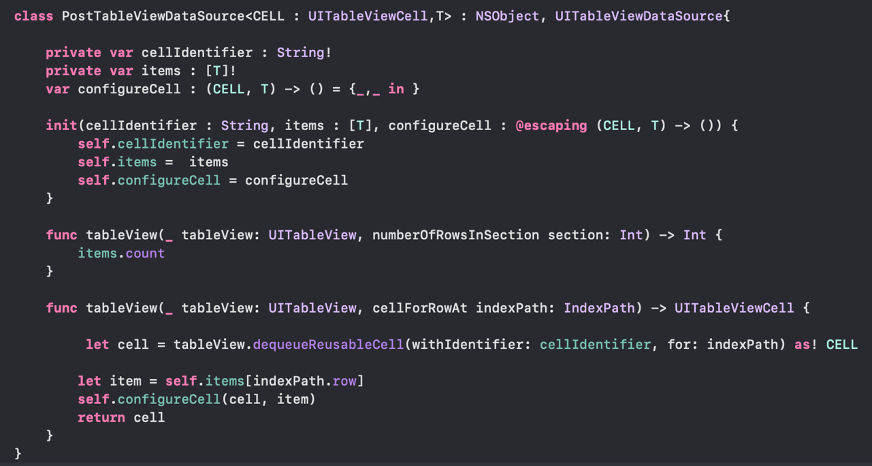
Code tersebut bisa digunakan secara global kalau seandainya kita memakai komponen UITableView dalam membangun aplikasi, untuk untuk menggunakannya kita panggil di view.
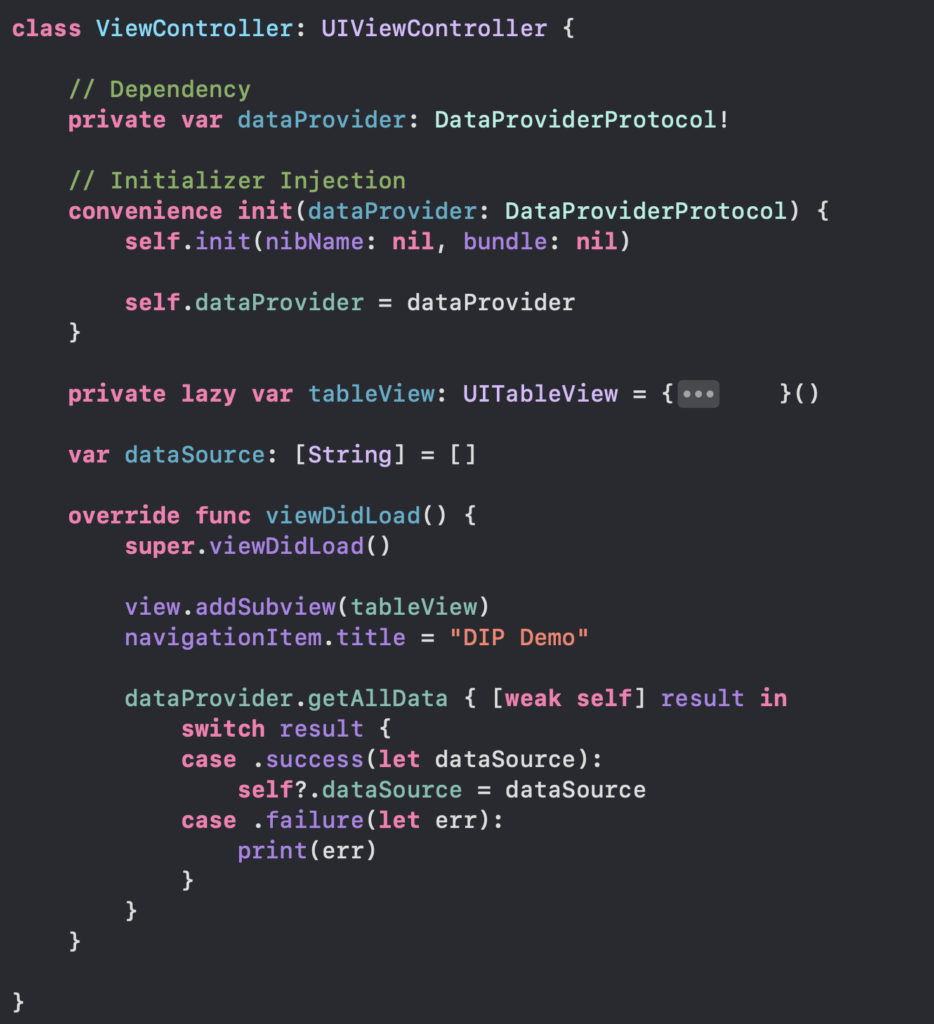
- Untuk coding di viewControllernya seperti dibawah ini
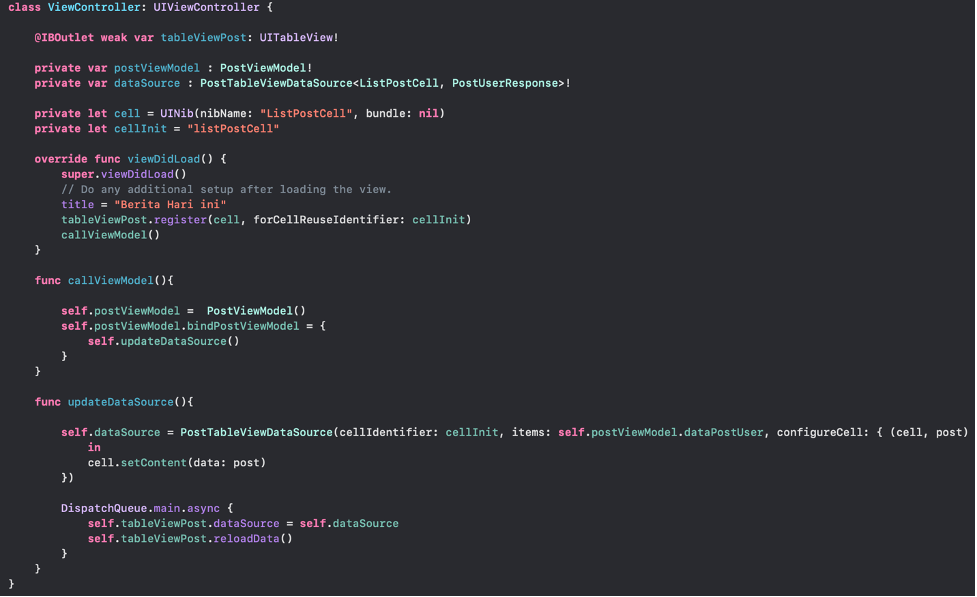
Jadi function yang telah kita set di view model tadi akan dieksekusi disini, jadi kalau terdapat perubahan dari ViewModel akan eksekusi function UpdateDataSource. Pada variable dataSource memanggil PostTableViewDataSource<ListPostCell, UserResponse>! yang berarti cell untuk tableView yang debut adalah ListPostCell dan data yang dipakai adalah UserResponse. Pada function UpdateDataSource di set lah identifier dari cell dan data yang pakai untuk ditampilkan.
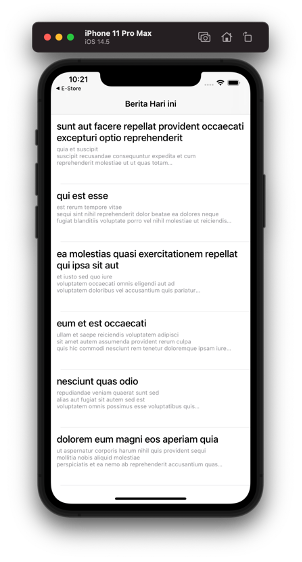
- Sehingga Hasilnya seperti ini