SSH Key-based Authentication adalah mekanisme otentikasi mengunakan SSH Key. SSH Key adalah sepasang kunci kriptografi (private key dan public key) yang dapat digunakan untuk melakukan otentikasi SSH client. Private key bersifat rahasia, harus disimpan oleh pemilik key dan tidak boleh diberikan kepada pihak lain. Sebaliknya, public key bersifat terbuka, boleh diberikan kepada pihak lain untuk melakukan otentikasi terhadap akses yang dilakukan oleh pemilih private key.
Lebih detail tentang cara kerja SSH Key-based authentication dapat dibaca disini.
Hai pasti teman-teman sudah sering dong kalian mendengar tentang istilah Testing Manifesto dan apa sih Testing Manifesto itu. Jadi Testing manifesto itu adalah suatu pengaruh atau kondisi yang di gunakan untuk mengukur dan meningkatkan suatu pengujian pada seorang tester. Setiap tester dapat mengevaluasi dan menginkatkan seberapa baik performa kita melakuakn software testing. Sedangkan jika kita masih mengunakan metode lama seperti waterfall yang testing selalu diakhir development dan bersifat linear, tester kesulitan untuk melakukan evaluasi untuk meningkatakan performa pengujian. Oleh karena itu mari kita cari tau poin-poin tentang Testing Manifesto.
kita pasti seringkali menggunakan Intent untuk navigasi antar activity di aplikasi, kita juga sering menggunakan fragmentManager untuk transaksi antar fragment. cara-cara itu memerlukan berbaris-baris kode apalagi jika terdapat konfigurasi lain seperti penambahan Extras atau penambahan animasi. selain itu navigasi nya juga tidak terstruktur sehingga kita terkadang bingung dengan alur navigasi di Aplikasi kita.
Pengembangan software yang kompleks tidak terlepas dari database yang kompleks pula, terdiri dari beberapa tabel yang berkesinambungan dan memiliki relasi satu sama lain, dalam dokumentasinya mysql di sebutkan seperti ini
By default, MySQL runs with autocommit mode enabled. This means that, when not otherwise inside a transaction, each statement is atomic, as if it were surrounded by START TRANSACTION and COMMIT. You cannot use ROLLBACK to undo the effect; however, if an error occurs during statement execution, the statement is rolled back.
secara default mysql berjalan dengan autocommit yang sudah diaktifkan, jadi setiap query akan dijalankan sesuai order namun jika ternyata di tengah tengah proses terjadi sesuatu error, yang mungkin bisa jadi disebabkan oleh terputusnya koneksi user atau karena hal lain, maka query yang sudah tereksekusi di awal tidak akan bisa dilakukan mekanisme rollback, maka dari itu diperlukan mekanisme database transaction, agar setiap rangkaian query yang kita harapkan jika terjadi kesalahan di tengah tengah maka proses dari awal dapat dibatalkan
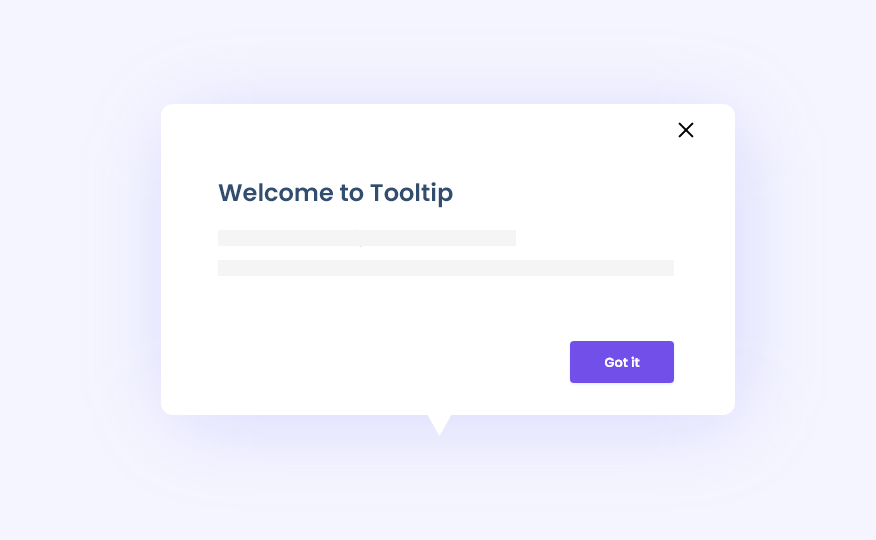
Apa yang anda lakukan jika anda membeli mainan rakitan, tetapi di dalam box mainan tersebut tidak ada kertas petunjuk merakitnya? kemungkinan besar anda akan merasa “bingung” bagaimana cara merakit mainan tersebut. atau jika anda berusaha merakit mainan tersebut, kemungkinan anda hanya akan “meraba” bagaimana cara merakitnya dan apakah rakitan mainan itu benar atau tidak..
Melalui analogi diatas, saya dapat mengatakan tooltip seperti petunjuk arah untuk platform yang anda buat. User akan merasa ditinggal sendiri “dijalan platform yang anda buat” tanpa petunjuk arah. Dan ketika user memutuskan untuk tetap di platform itu, user anda akan bingung karena meraba atau kemungkinan terburuknya bisa jadi user memilih untuk berhenti menggunakan paltform dan mencari alternatif aplikasi yang lebih mudah dipahami.
Mari kita kenal lebih dalam mengenai apa itu tooltip, kasus penggunaannya dan tips membuat tooltip.
Dalam membuat aplikasi, kita pasti akan menguji aplikasi nya apakah ada error atau bug pada kode yang kita tuliskan. Pasti kita butuh berkali-kali melakukan pengujian aplikasi baru bisa bebas dari error atau bug, yang berarti kita harus menjalankan berkali-kali prosedur pengujian. akan cukup melelahkan jika kita melakukan pengujian secara manual dan bisa juga ada pengujian yang terlewatkan. Sebenarnya ada fitur pengujian otomatis di Android yang bernama Instrumentation Testing atau UI Testing, fitur yang memungkinkan kita melakukan pengujian secara otomatis pada aplikasi secara berurutan berdasarkan perintah yang kita berikan. namun kita perlu belajar perintah-perintah pengujiannya untuk dapat menggunakan Instrumentation Testing dan tentunya kita perlu melakukan koding lagi untuk membuat pengujian. cukup melelahkan bagi beberapa orang karena harus ngoding lagi.
Microservices adalah arsitektur yang digunakan untuk mengembangkan system yang dibagi menjadi bagian-bagian kecil / modular dan memungkinkan teknologi yang digunakan berbeda sesuai kebutuhan dan kemudahan dalam satu system. Di dalam microservices memungkinkan setiap fitur dikembangkan dengan teknologi yang berbeda baik dari skema Database ataupun Bahasa Pemrograman. Microservices sering digunakan oleh pada system produk yang memiliki skala yang besar, kompleksitas dan transfer rate yg sangat besar.
Diketahui aplikasi yang menggunakan Microservices Gojek, Grab, Tokopedia, Shopee, Paypal , Twitter, Netflix dan lain lain.
Namun melakukan backup dengan perintah tersebut menimbulkan beberapa masalah, yaitu:
Bagaimana bila ada database yang tidak ingin kita backup, misalnya default database seperti information_schema, mysql, performance_schema, atau sys?
Bagaimana bila kita ingin melakukan restore database tertentu saja?
Bagaimana bila kita ingin melakukan backup rutin setiap hari?
Dalam tulisan ini, saya akan tunjukkan contoh backup script sederhana yang dapat melakukan backup database MySQL secara otomatis sekaligus menyelesaikan permasalahan tersebut.
Sesuai namanya, “bash aliases” digunakan untuk membuat alias sebuah perintah. Misalnya, kita ingin membuat alias untuk perintah menampilkan file dalam current directory berurutan berdasarkan ukuran berikut ini
$ du -hs * | sort -h
Kita dapat membuat alias untuk perintah tersebut dengan perintah alias seperti contoh berikut ini
$ alias dusort='du -hs * | sort -h'
Setelah membuat alias, kita bisa menjalankan alias tersebut sehingga tidak perlu lagi mengetikkan perintah yang panjang seperti sebelumnya.
SwiftUI ialah framework UI baru yang dikenal oleh apple semenjak iOS 13 pada WWDC2019. SwiftUI ini sendiri bersifat deklaratif sehingga gampang sekali untuk membuat UI dengan framework ini. Selain itu SwiftUI juga memiliki fitur yang sangat menarik yaitu kemampuan untuk MultiPlatform, yaitu sekali coding SwiftUI mampu berjalan di iPhone, iPad, MacOS serta AppleWatch.
Menurut saya sendiri, SwiftUI akan semakin banyak digunakan oleh developer yang ada di dunia. Pada WWDC kemarin sendiri, weather app pada iOS 15 sudah ditulis ulang menggunakan SwiftUI sendiri. Hal ini memungkinkan bahwa SwiftUI cukup stable untuk dilanjutkan pada tahap production.
Ayo kita telusuri SwiftUI bersama-sama
Hands On
Pada artikel ini kita akan mencoba membuat sebuah aplikasi list contact sederhana untuk mendemontrasikan seberapa gampang membuat UI dengan framework ini sendiri.
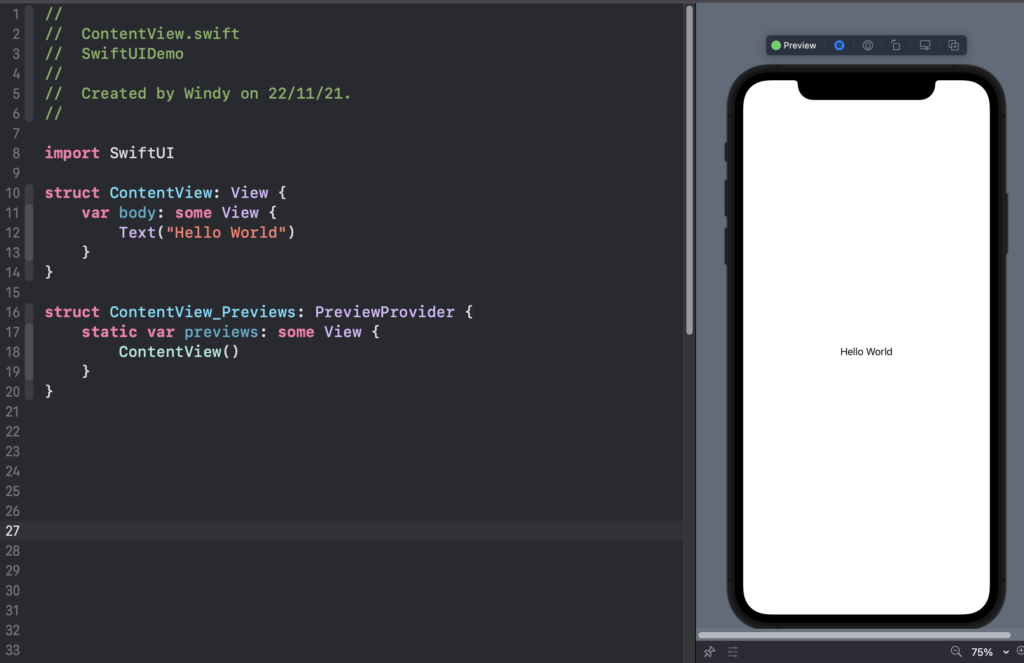
Ini merupakan template default dari SwiftUI sendiri, pada SwiftUI kita sudah tidak mengenal Storyboard hahaha. Kodingan yang diperlukan untuk membuat UI akan kita tulis pada bagian body.
Default Template
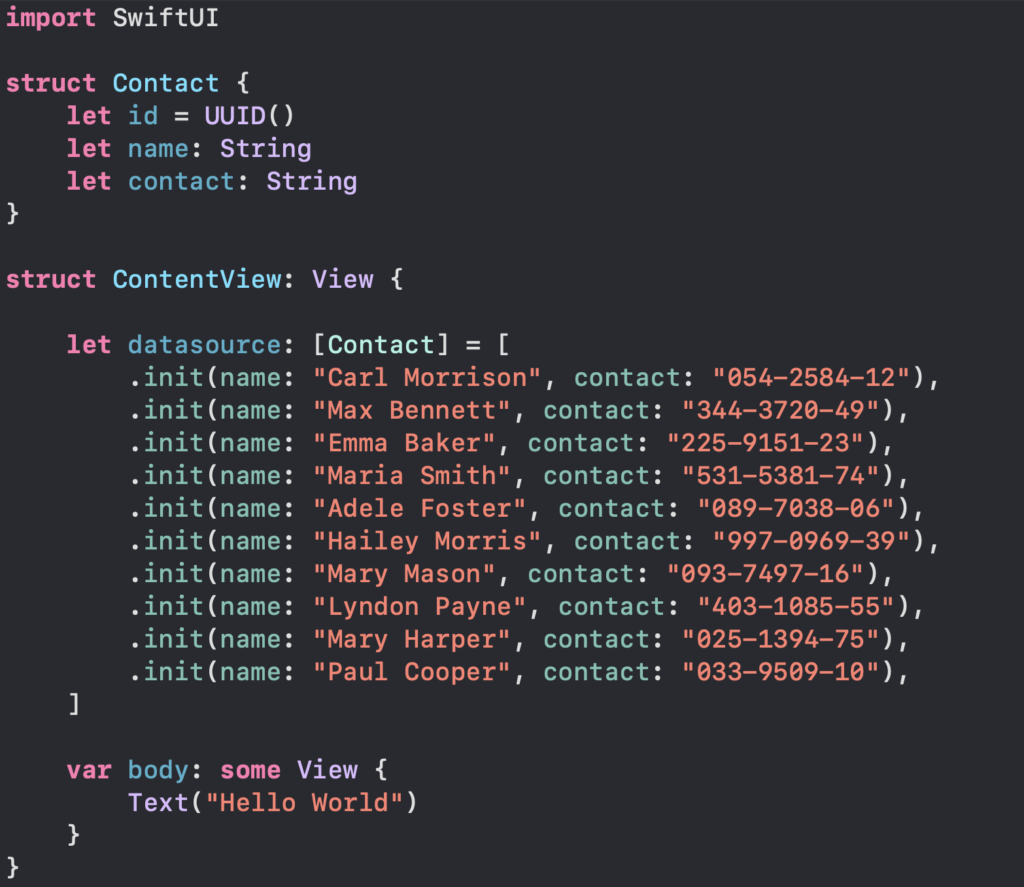
Prepare Dummy Data
Ayo kita menyiapkan dummy data kita seperti ini
Dummy Data
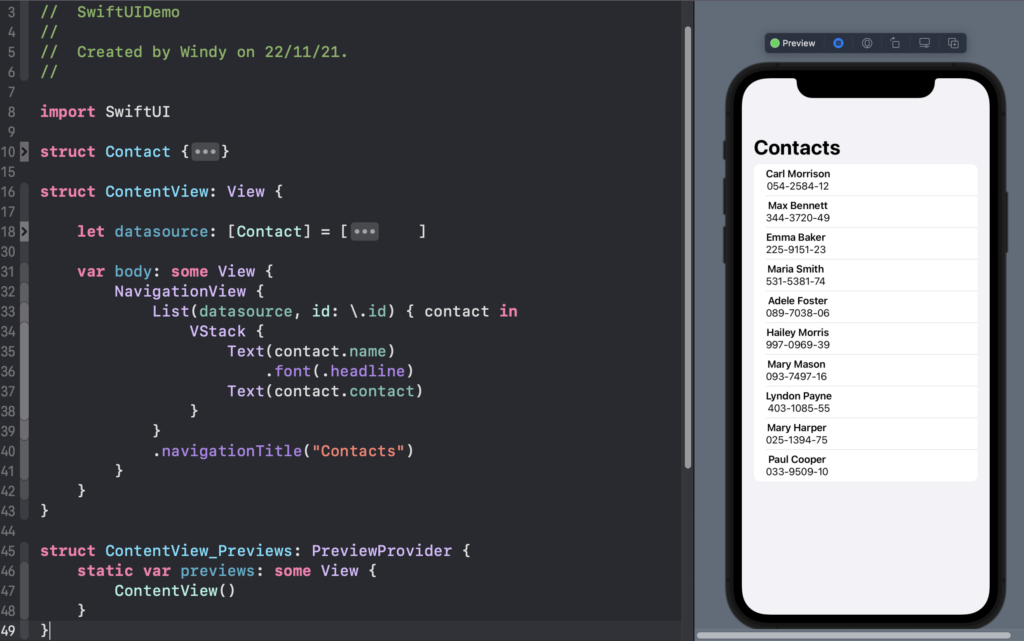
Membuat List
Bahkan untuk membuat tampilan list sederhana kita hanya perlu kode kurang dari 10 baris
List
Hanya dengan beberapa baris kode, kita sudah dapat membuat UI dengan sangat gampang. Apabila kita menggunakan UIKit, maka teman-teman sudah bisa menebaknya. Kita harus melakukan setup dengan UITableViewDataSource dan UITableViewDelegate kemudian kita juga perlu membuat tableviewcell serta kita juga perlu berurusan dengan autolayout.
Kesimpulan
Semoga dengan contoh seperti ini dapat memberikan gambaran seberapa powerful SwiftUI ini. Walaupun SwiftUI ini sendiri belum akan digunakan pada waktu yang dekat, namun SwiftUI ini sendiri dapat menjadi investasi yang baik untuk masa depan. Berikut referensi video pertama kali SwiftUI diperkenalan pada WWDC2019.